Small. Fast. Reliable.
Choose any three.
Choose any three.
FTS3和FTS4是SQLite虚拟表模块,允许用户对一组文档执行全文搜索。描述全文搜索的最常见(最有效)方式是“ Google,Yahoo和Bing对放置在万维网上的文档的处理方式”。用户输入一个或多个术语,可能是由二元运算符连接或组合在一起组成一个短语,而全文查询系统会根据用户指定的运算符和分组来查找与这些术语最匹配的文档集。本文介绍了FTS3和FTS4的部署和使用。
FTS1和FTS2是SQLite的过时全文搜索模块。这些较旧的模块存在已知问题,应避免使用它们。FTS3原始代码的一部分由Google的Scott Hess贡献给SQLite项目。现在,它已作为SQLite的一部分进行开发和维护。
FTS3和FTS4扩展模块允许用户使用内置的全文本索引创建特殊表(以下称为“ FTS表”)。全文索引使用户可以有效地查询数据库中包含一个或多个单词的所有行(以下称“令牌”),即使该表包含许多大型文档也是如此。
例如,如果“安然电子邮件数据集”中的每个517430文档都插入到FTS表和使用以下SQL脚本创建的普通SQLite表中:
使用fts3(content TEXT)创建虚拟表enrondata1; / * FTS3表* / 创建表enrondata2(content TEXT); / *普通表* /
然后,可以执行以下两个查询中的任何一个,以查找数据库中包含单词“ linux”的文档数(351)。使用一种台式PC硬件配置,对FTS3表的查询将在大约0.03秒内返回,而查询普通表的查询为22.5秒。
SELECT count(*)从enrondata1那里匹配MATCH'Linux'; / * 0.03秒* / SELECT count(*)从enrondata2,其中内容类似于'%linux%';/ * 22.5秒* /
当然,以上两个查询并不完全等效。例如,LIKE查询匹配包含诸如“ linuxophobe”或“ EnterpriseLinux”之类的词的行(实际上,Enron电子邮件数据集实际上不包含任何此类词),而FTS3表上的MATCH查询仅选择那些词。包含“ linux”作为离散标记的行。两种搜索都不区分大小写。FTS3表在磁盘上的消耗约为2006 MB,而普通表仅消耗1453 MB。使用与执行上面的SELECT查询相同的硬件配置,FTS3表的填充时间不到31分钟,而普通表的填充时间为25分钟。
FTS3和FTS4几乎相同。它们共享大多数代码,并且它们的接口是相同的。不同之处在于:
FTS4包含查询性能优化,可以显着提高全文查询的性能,这些全文查询包含非常常见的术语(在表行中占很大比例)。
FTS4支持可以与matchinfo() 函数一起使用的一些其他选项。
因为FTS4表将额外的信息存储在两个新的影子表中的磁盘上 以支持性能优化和额外的matchinfo()选项,所以与使用FTS3创建的等效表相比,FTS4表可能消耗更多的磁盘空间。通常,开销为1-2%或更少,但是如果FTS表中存储的文档非常小,则开销可能高达10%。通过在FTS4表声明中指定指令“ matchinfo = fts3”可以减少开销,但这是以牺牲一些额外支持的matchinfo()选项为代价的。
FTS4提供了挂钩(compress和uncompress 选项),允许以压缩形式存储数据,从而减少了磁盘使用量和IO。
FTS4是FTS3的增强。从SQLite版本3.5.0(2007-09-04)开始,FTS3已可用。在SQLite版本3.7.4 (2010-12-07)中添加了FTS4的增强功能。
您应在应用程序中使用哪个模块FTS3或FTS4?FTS4有时会比FTS3快很多,甚至快几个数量级(取决于查询),尽管在通常情况下,两个模块的性能是相似的。FTS4还提供了增强的matchinfo()输出,可用于对MATCH操作的结果进行排名。另一方面,在缺少matchinfo = fts3指令的情况下,FTS4比FTS3需要更多的磁盘空间,尽管在大多数情况下仅占百分之二。
对于较新的应用程序,建议使用FTS4。尽管如果要与旧版本的SQLite兼容很重要,那么FTS3通常也可以使用。
与其他虚拟表类型一样,使用CREATE VIRTUAL TABLE语句创建新的FTS表 。在USING关键字之后的模块名称为“ fts3”或“ fts4”。虚拟表模块自变量可以保留为空,在这种情况下,将创建带有单个用户定义列名为“ content”的FTS表。可选地,模块自变量可以被传递以逗号分隔的列名的列表。
如果作为CREATE VIRTUAL TABLE语句的一部分为FTS表显式提供了列名,则可以选择为每个列指定数据类型名。这是纯语法糖,FTS或SQLite核心不会出于任何目的使用提供的类型名。这同样适用于与FTS列名称一起指定的任何约束-系统会分析它们但不以任何方式使用或记录这些约束。
-创建一个名为“数据”的FTS表,其中一列为“内容”: 使用fts3()创建虚拟表数据; -用三列创建一个名为“ pages”的FTS表: 使用fts4(标题,关键字,正文)创建虚拟表页面; -创建一个带有两列的名为“ mail”的FTS表。资料类型 -和列约束与每个列一起指定。这些 -FTS和SQLite完全忽略了它们。 使用fts3创建虚拟表邮件 subject VARCHAR(256)NOT NULL, 正文TEXT CHECK(length(body)<10240) );
除了列的列表之外,传递给用于创建FTS表的CREATE VIRTUAL TABLE语句的模块参数也可以用于指定标记器。通过指定形式为“ tokenize = <tokenizer名称> <tokenizer args>”的字符串代替列名来完成此操作,其中<tokenizer name>是要使用的令牌生成器的名称,而<tokenizer args>是可选的空格分隔的限定符列表,以传递给令牌生成器实现。标记符规范可以放在列列表中的任何位置,但是每个CREATE VIRTUAL TABLE语句最多允许一个标记符声明。有关使用(以及在必要时实施)标记器的详细说明,请参见下文。
-创建一个名为“ papers”的FTS表,该表有两列使用 -分词器“ porter”。 使用fts3(作者,文档,tokenize = porter)创建虚拟表文件; -用单列-“内容”创建一个使用 “简单”标记器的FTS表。 使用fts4(tokenize = simple)创建虚拟表数据; -创建一个包含两列使用“ icu”令牌生成器的FTS表。 -将限定符“ en_AU”传递给令牌生成器实现 使用fts3(a,b,tokenize = icu en_AU)创建虚拟表名称;
可以使用普通的DROP TABLE 语句从数据库中删除FTS表。例如:
-创建,然后立即删除FTS4表。 使用fts4()创建虚拟表数据; DROP TABLE数据;
使用INSERT,UPDATE和DELETE 语句填充FTS表,方式与普通SQLite表相同。
除了用户命名的列(如果未在CREATE VIRTUAL TABLE 语句的一部分中指定模块自变量的情况下,也称为“内容”列),每个FTS表都具有“行”列。FTS表的rowid的行为与普通SQLite表的rowid列相同,不同之处在于,如果使用VACUUM命令重建数据库,则FTS表的rowid列中存储的值保持不变。对于FTS表,允许使用“ docid”作为别名以及通常的“ rowid”,“ oid”和“ _oid_”标识符。尝试使用表中已经存在的docid值插入或更新行是错误的,就像普通的SQLite表一样。
rowid列的“ docid”和普通SQLite别名之间还有一个细微的区别。通常,如果INSERT或UPDATE语句将离散值分配给rowid列的两个或多个别名,则SQLite会将INSERT或UPDATE语句中指定的此类值的最右边写入数据库。但是,在插入或更新FTS表时,同时为“ docid”和一个或多个SQLite rowid别名分配一个非NULL值被认为是错误的。请参阅下面的示例。
-创建FTS表 使用fts4(title,body)创建虚拟表页面; -插入具有特定docid值的行。 INSERT INTO pages(docid,title,body)VALUES(53,'Home Page','SQLite is a software ...'); -插入一行,并允许FTS使用与 SQLite用于普通表 相同的算法分配docid值。在这种情况下,新的docid将为54,比表格中当前存在的最大docid大一。 插入页面(标题,正文)VALUES('下载','所有SQLite源代码...'); -更改刚插入的行的标题。 UPDATE页面SET title ='Download SQLite'WHERE rowid = 54; -删除整个表格内容。 从页面删除; -以下是错误。不能同时 为FTS表的rowid和docid列分配非NULL值。 插入页面(rowid,docid,title,body)VALUES(1、2,'A title','A document body');
为了支持全文查询,FTS维护一个反向索引,该索引将从数据集中出现的每个唯一术语或单词映射到表内容中出现的位置。出于好奇,下面显示了用于在数据库文件中存储此索引的数据结构的完整描述。这种数据结构的一个特点是,数据库在任何时候都可能不包含一个索引b树,而是包含几个不同的b树,这些树在插入,更新和删除行时逐渐合并。写入FTS表时,此技术可提高性能,但会给使用索引的全文查询带来一些开销。评估特殊的“优化”命令,即“ INSERT INTO <fts-table>(<fts-table>)VALUES('optimize')”形式的SQL语句,导致FTS将所有现有索引b树合并为包含整个索引树的单个大b树指数。这可能是一项昂贵的操作,但可能会加快将来的查询速度。
例如,为名为“ docs”的FTS表优化全文索引:
-优化FTS表“ docs”的内部结构。 插入docs(docs)VALUES('optimize');
上面的陈述对某些人来说可能在语法上是不正确的。有关说明,请参阅描述简单fts查询的部分。
还有另一种不赞成使用SELECT语句调用优化操作的方法。新代码应使用类似于上述INSERT的语句来优化FTS结构。
对于所有其他虚拟或其他SQLite表,使用SELECT语句从FTS表中检索数据。
使用两种不同形式的SELECT语句可以有效地查询FTS表:
通过rowid查询。如果SELECT语句的WHERE子句包含形式为“ rowid =?”的子句,则其中?是SQL表达式,FTS可以使用SQLite INTEGER PRIMARY KEY索引的等效项直接检索请求的行。
全文查询。如果SELECT语句的WHERE子句包含形式为“ <column> MATCH?”的子句,则FTS能够使用内置的全文本索引来将搜索限制为与全文本匹配的那些文档。查询字符串,指定为MATCH子句的右侧操作数。
如果无法使用这两种查询策略,则将使用对整个表的线性扫描来实现FTS表上的所有查询。如果表中包含大量数据,这可能是不切实际的方法(此页上的第一个示例显示,使用现代PC进行1.5 GB数据的线性扫描大约需要30秒)。
-此块中的示例假定以下FTS表: 使用fts3(主题,正文)创建虚拟表邮件; SELECT * FROM mail WHERE rowid = 15; - 快速地。Rowid查找。 SELECT * FROM mail WHERE body MATCH'sqlite'; - 快速地。全文查询。 选择*从邮件WHERE邮件匹配“搜索”; - 快速地。全文查询。 SELECT * FROM 15至20之间的rowid邮件; - 快速地。Rowid查找。 SELECT * FROM mail WHERE subject ='database'; - 慢的。线性扫描。 SELECT * FROM mail WHERE subject MATCH'database'; - 快速地。全文查询。
在上面所有的全文查询中,MATCH运算符的右侧操作数是由单个术语组成的字符串。在这种情况下,对于包含一个或多个指定单词实例(“ sqlite”,“ search”或“ database”,取决于您查看的示例)的所有文档,MATCH表达式的计算结果均为true。将单个术语指定为MATCH运算符的右侧操作数会导致最简单和最常见的全文查询类型。但是,更复杂的查询是可能的,包括短语搜索,术语前缀搜索以及对包含在彼此定义的邻近范围内出现的术语组合的文档的搜索。下面描述查询全文索引的各种方式 。
通常,全文查询不区分大小写。但是,这取决于要查询的FTS表使用的特定标记器。有关详细信息,请参阅令牌生成器部分。
上面的段落指出,带有简单术语作为右侧操作数的MATCH运算符对包含指定术语的所有文档的计算结果均为true。在这种情况下,“文档”可以指存储在FTS表的一行的单个列中的数据,也可以指单个行中所有列的内容,具体取决于用作左侧操作数的标识符到MATCH运算符。如果指定为MATCH运算符的左侧操作数的标识符是FTS表列名称,则必须包含搜索项的文档就是存储在指定列中的值。但是,如果标识符是FTS表的名称本身,则MATCH运算符对FTS表的每一行的任何列包含搜索项的结果都为true。下面的示例演示了这一点:
-示例架构 使用fts3(主题,正文)创建虚拟表邮件; -表人口示例 INSERT INTO mail(docid,subject,body)VALUES(1,'软件反馈','发现它太慢'); INSERT INTO mail(docid,subject,body)VALUES(2,'软件反馈','无反馈'); INSERT INTO mail(docid,subject,body)VALUES(3,'slow Lunch order','was a software problem'); -示例查询 SELECT * FROM mail WHERE主题MATCH'software'; -选择第1行和第2行 SELECT * FROM mail WHERE body MATCH'feedback'; -选择第2行 SELECT * FROM mail WHERE mail MATCH'software'; -选择行1、2和3 SELECT * FROM mail WHERE mail MATCH'slow'; -选择第1行和第3行
乍一看,上面的示例中的最后两个全文查询在语法上似乎是不正确的,因为有一个表名(“ mail”)用作SQL表达式。可以接受的原因是,每个FTS表实际上都有一个HIDDEN列,其名称与表本身相同(在本例中为“ mail”)。存储在此列中的值对应用程序没有意义,但可以用作MATCH运算符的左侧操作数。该特殊列也可以作为参数传递给FTS辅助功能。
以下示例说明了上述内容。表达式“ docs”,“ docs.docs”和“ main.docs.docs”均指“ docs”列。但是,表达式“ main.docs”不引用任何列。它可以用来引用表,但是在下面使用表的上下文中,表名是不允许的。
-示例架构 使用fts4(content)创建虚拟表文档; -查询示例 SELECT * FROM docs WHERE docs MATCH'sqlite'; - 好的。 SELECT * FROM docs在docs.docs匹配'sqlite'; - 好的。 SELECT * FROM docs WHERE main.docs.docs MATCH'sqlite'; - 好的。 SELECT * FROM docs WHERE main.docs MATCH'sqlite'; - 错误。
从用户的角度来看,FTS表在许多方面类似于普通的SQLite表。就像使用普通表一样,可以使用INSERT,UPDATE和DELETE命令在FTS表中添加,修改和删除数据。同样,SELECT命令可用于查询数据。以下列表总结了FTS和普通表之间的区别:
与所有虚拟表类型一样,无法创建附加到FTS表的索引或触发器。也不能使用ALTER TABLE命令向FTS表添加额外的列(尽管可以使用ALTER TABLE重命名FTS表)。
作为创建FTS表的“ CREATE VIRTUAL TABLE”语句的一部分指定的数据类型将被完全忽略。在存储之前,所有插入FTS表列(特殊的rowid列除外)的值都将转换为TEXT类型,而不是对插入的值应用类型亲和力的一般规则。
FTS表允许使用特殊别名“ docid”来引用所有虚拟表支持的rowid列。
该FTS MATCH运算符支持基于内建的全文索引的查询。
该FTS辅助功能,片断() ,偏移量() ,和matchinfo()可用于支持全文查询。
每个FTS表都有一个隐藏的列,其名称与表本身相同。隐藏列的每一行中包含的值是一个Blob,仅可用作MATCH运算符的左操作数 或FTS辅助功能之一的最左参数。
尽管FTS3和FTS4包含在SQLite核心源代码中,但默认情况下未启用它们。要构建启用了FTS功能的SQLite,请在编译时定义预处理程序宏SQLITE_ENABLE_FTS3。新的应用程序还应该定义SQLITE_ENABLE_FTS3_PARENTHESIS宏以启用 增强的查询语法(请参见下文)。通常,这是通过在编译器命令行中添加以下两个开关来完成的:
-DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_FTS3_PARENTHESIS
请注意,启用FTS3也会使FTS4可用。没有单独的SQLITE_ENABLE_FTS4编译时选项。SQLite的版本要么支持FTS3和FTS4,要么不支持。
如果使用基于融合自动配置的构建系统,则在运行“配置”脚本时设置CPPFLAGS环境变量是设置这些宏的简便方法。例如,以下命令:
CPPFLAGS =“-DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_FTS3_PARENTHESIS”。/configure <配置选项>
其中,<configure options>是通常传递给configure脚本的那些选项(如果有)。
由于FTS3和FTS4是虚拟表,因此SQLITE_ENABLE_FTS3编译时选项与SQLITE_OMIT_VIRTUALTABLE选项不兼容。
如果SQLite的构建不包含FTS模块,则任何准备SQL语句以创建FTS3或FTS4表或以任何方式删除或访问现有FTS表的尝试都将失败。返回的错误消息将类似于“没有这样的模块:ftsN”(其中N为3或4)。
如果ICU库的C版本 可用,则FTS也可以使用已定义的SQLITE_ENABLE_ICU预处理程序宏进行编译。使用此宏进行编译可以使FTS 令牌生成器使用ICU库,使用指定语言和区域设置的约定将文档拆分为术语(单词)。
-DSQLITE_ENABLE_ICU
关于FTS表,最有用的是可以使用内置的全文本索引执行的查询。通过指定形式为“ <column> MATCH <全文查询表达式>”的子句来执行全文查询,这是从FTS表中读取数据的SELECT语句的WHERE子句的一部分。 上面介绍了返回所有包含给定术语的所有文档的简单FTS查询。在该讨论中,MATCH运算符的右侧操作数被假定为由单个项组成的字符串。本节描述FTS表支持的更复杂的查询类型,以及如何通过将更复杂的查询表达式指定为MATCH运算符的右侧操作数来利用它们。
FTS表支持三种基本查询类型:
令牌或令牌前缀查询。可以查询包含指定术语的所有文档的FTS表(上述简单情况),或包含带有指定前缀的术语的所有文档。如我们所见,特定术语的查询表达式只是该术语本身。用于搜索术语前缀的查询表达式是前缀本身,后面带有“ *”字符。例如:
-虚拟表声明 使用fts3(title,body)创建虚拟表文档; -查询所有包含“ linux”一词的文档: SELECT * FROM docs WHERE docs MATCH'linux'; -查询所有包含带有前缀“ lin”的术语的文档。这将匹配 -包含“ linux”的所有文档,也包含包含“ linear”, “ linker”,“ linguistic”等术语的文档。 SELECT * FROM docs WHERE docs MATCH'lin *';
通常,将令牌或令牌前缀查询与指定为MATCH运算符左侧的FTS表列进行匹配。或者,如果针对所有列指定了与FTS表本身名称相同的特殊列。可以通过在基本术语查询之前指定列名后跟“:”字符来覆盖此设置。“:”和要查询的词之间可能有空格,但列名和“:”字符之间不能有空格。例如:
-在数据库中查询在 文档标题中 出现“ linux”一词的文档,在文档标题或正文中出现“问题”一词。 SELECT * FROM docs WHERE docs MATCH'title:linux Problems'; -在数据库中查询在 文档标题中 出现“ linux”一词的文档,并且在文档正文中出现“驱动程序”一词-(“驱动程序”也可能出现在标题中,但这单靠不满足 -查询条件)。 SELECT * FROM docs WHERE body MATCH'title:linux driver';
如果FTS表是FTS4表(不是FTS3),则标记也可以带有“ ^”字符作为前缀。在这种情况下,为了匹配令牌,令牌必须作为匹配行的任何列中的第一个令牌出现。例子:
-所有文档,其中“ linux”是至少一个 -列的第一个标记。 SELECT * FROM docs WHERE docs MATCH'^ linux'; -在“标题”列中第一个标记为其开头的所有文档以“ lin”开头。 SELECT * FROM docs WHERE body MATCH'title:^ lin *';
词组查询。词组查询是一种查询,该查询以指定顺序检索包含指定术语或术语前缀集的所有文档,且中间没有标记。短语查询是通过用双引号(“)括起来的用空格分隔的术语或术语前缀序列来指定的。例如:
-查询所有包含短语“ Linux应用程序”的文档。 SELECT * FROM docs WHERE docs MATCH'“ linux applications”'; -查询所有包含短语匹配“ lin * app *”的文档。以及 “ Linux应用程序”,它也将匹配常用短语,例如“油毡装置” 或“链接学徒”。 SELECT * FROM docs WHERE docs MATCH'“ lin * app *”';
NEAR查询。NEAR查询是一种查询,该查询返回的文档包含彼此指定的接近度内的两个或多个指定术语或短语(默认情况下,包含10个或更少的中间术语)。通过在两个词组,标记或标记前缀查询之间放置关键字“ NEAR”来指定NEAR查询。要指定默认值以外的其他值,可以使用格式为“ NEAR / <N> ”的运算符,其中 <N>是允许的最大插入词数。例如:
-虚拟表声明。 使用fts4()创建虚拟表文档; -虚拟表数据。 INSERT INTO docs VALUES(“ SQLite是符合ACID的嵌入式关系数据库管理系统”); -搜索包含术语“ sqlite”和“数据库”以及 不超过10个中间术语 的文档。这与table docs 中的唯一文档匹配(因为文档中“ SQLite”和“ database”之间只有六个术语)。 SELECT * FROM docs WHERE docs MATCH'sqlite NEAR database'; -搜索包含术语“ sqlite”和“数据库”以及 不超过6个中间术语 的文档。这也匹配-table docs 中的唯一文档。请注意,这些术语在文档中出现的顺序-不必与它们在查询中出现的顺序相同。 SELECT * FROM docs WHERE docs MATCH'database NEAR / 6 sqlite'; -搜索包含术语“ sqlite”和“数据库”以及 不超过5个中间术语的文档。该查询没有匹配的文档。 SELECT * FROM docs WHERE docs MATCH'database NEAR / 5 sqlite'; -搜索包含短语“ ACID compatible”和术语 “ database”(其中不超过2个术语将二者分开)的 文档。这与表文档中存储的-文档匹配。 SELECT * FROM docs WHERE docs MATCH'database NEAR / 2“ ACID compatible”“; -搜索包含短语“符合ACID”和术语 “ sqlite” 的文档,其中用不超过2个术语将两者分开。这也匹配-表文档中存储的唯一文档。 SELECT * FROM docs WHERE docs MATCH'“符合ACID” NEAR / 2 sqlite';
一个查询中可能会出现多个NEAR运算符。在这种情况下,由NEAR运算符分隔的每对术语或短语必须出现在文档中彼此指定的接近范围内。使用与上面的示例块相同的表和数据:
-以下查询选择的文档包含以下术语的实例 :“ sqlite”与实例“ acid”的实例以两个或更少的术语分隔,而“ acidite”又与实例中的 两个或更少的术语相分隔术语的 “关系”。 SELECT * FROM docs WHERE docs MATCH'sqlite NEAR / 2 acid NEAR / 2 Relational'; -此查询不匹配任何文档。术语“ sqlite” 的实例与“酸”的实例足够接近,但 与“关系”的实例足够不接近。 SELECT * FROM docs WHERE docs MATCH'acid NEAR / 2 sqlite NEAR / 2 Relational';
短语和NEAR查询可能不会跨越一行中的多个列。
上面描述的三种基本查询类型可用于查询全文索引,以查找与指定条件匹配的文档集。使用FTS查询表达语言,可以对基本查询的结果执行各种设置操作。当前支持三种操作:
FTS模块可以被编译为使用全文查询语法的两个略有不同的版本之一,即“标准”查询语法和“增强”查询语法。上面描述的基本术语,术语前缀,短语和NEAR查询在两种语法版本中都是相同的。指定设置操作的方式略有不同。以下两个小节描述了两种查询语法中与集合操作有关的部分。有关编译说明,请参阅有关如何编译fts的描述。
增强的查询语法支持AND,OR和NOT二进制集运算符。运算符的两个操作数中的每一个都可以是基本的FTS查询,也可以是另一个AND,OR或NOT设置操作的结果。必须使用大写字母输入操作员。否则,它们将被解释为基本术语查询,而不是集合运算符。
可以隐式指定AND运算符。如果出现两个基本查询,并且没有运算符将它们分隔在FTS查询字符串中,则结果与两个基本查询由AND运算符分隔的结果相同。例如,查询表达式“隐式运算符”是“隐式AND运算符”的更为简洁的版本。
-虚拟表声明 使用fts3()创建虚拟表文档; -虚拟表数据 INSERT INTO docs(docid,content)VALUES(1,'数据库是一个软件系统'); INSERT INTO docs(docid,content)VALUES(2,'sqlite是一个软件系统'); INSERT INTO docs(docid,content)VALUES(3,'sqlite是一个数据库'); -返回包含术语“ sqlite”和 -术语“数据库”的文档集。此查询将仅返回文档ID为3的文档。 SELECT * FROM docs WHERE docs MATCH'sqlite AND database'; -再次,返回同时包含“ sqlite”和 “数据库” 的文档集。这次,使用隐式AND运算符。同样,文档-3是此查询匹配的唯一文档。 SELECT * FROM docs WHERE docs MATCH'database sqlite'; -查询包含“ sqlite”或“数据库”的文档集。 -此查询匹配数据库中的所有三个文档。 SELECT * FROM docs WHERE docs MATCH'sqlite OR database'; -查询所有包含术语“数据库”但不包含 术语“ sqlite”的文档。文档1是唯一符合此条件的文档。 SELECT * FROM docs WHERE docs MATCH'database NOT sqlite'; -以下查询与任何文档均不匹配。因为“和”使用小写字母, 所以它被解释为基本术语查询,而不是运算符。运营商必须 -使用大写字母指定。实际上,此查询将匹配任何 包含至少三个术语“数据库”,“和”和“ sqlite”中的每一个的 文档。-上面的示例数据中没有文档符合此条件。 SELECT * FROM docs WHERE docs MATCH'database and sqlite';
上面的所有示例都使用基本的全文术语查询作为所展示的set操作的两个操作数。短语和NEAR查询也可以使用,其他设置操作的结果也可以使用。当FTS查询中存在多个设置操作时,运算符的优先级如下:
| 操作员 | 增强的查询语法优先级 |
|---|---|
| 不是 | 最高优先级(最紧密的分组)。 |
| 和 | |
| 或者 | 最低优先级(最松散的分组)。 |
使用增强的查询语法时,可以使用括号来覆盖各种运算符的默认优先级。例如:
-返回与包含
两个术语“ sqlite”和“数据库”和/或包含术语“库”的所有文档关联的docid值。
从文档中选择docid,在文档中匹配“ sqlite AND database OR library”;
-此查询与上面的查询相同。
从文档中选择docid,在文档中匹配“ sqlite和数据库”
联盟
从文档中选择docid,在文档中匹配“库”;
-查询包含术语“ linux”以及至少
-短语“ sqlite数据库”和“ sqlite库”之一的文档集。
从文档中选择docid,在文档中匹配'(“ sqlite数据库”或“ sqlite库”)AND linux';
-此查询与上面的查询相同。
从文档中选择docid,在文档中匹配“ Linux”
相交
SELECT docid FROM(
从文档中选择docid,在文档中匹配“ SQLite库”
联盟
从文档中选择docid,在文档中匹配“'sqlite数据库”'
);
使用标准查询语法的FTS查询设置操作与使用增强查询语法的设置操作相似但不相同。有四个区别,如下所示:
仅支持AND运算符的隐式版本。将字符串“ AND”指定为标准查询语法查询的一部分将解释为对包含术语“和”的文档集的术语查询。
不支持括号。
不支持NOT运算符。标准查询语法代替NOT运算符,而是支持一元“-”运算符,该运算符可应用于基本术语和术语前缀查询(但不适用于短语或NEAR查询)。带有一元“-”运算符的术语或术语前缀可能不会显示为OR运算符的操作数。FTS查询可能不完全由附加了一元“-”运算符的术语或术语前缀查询组成。
-搜索包含术语“ sqlite”但 不包含术语“数据库”的文档集。 SELECT * FROM docs WHERE docs MATCH'sqlite -database';
设置操作的相对优先级不同。特别是,使用标准查询语法,“ OR”运算符的优先级高于“ AND”运算符。使用标准查询语法时,运算符的优先级为:
| 操作员 | 标准查询语法优先级 |
|---|---|
| 一元“-” | 最高优先级(最紧密的分组)。 |
| 或者 | |
| 和 | 最低优先级(最松散的分组)。 |
-搜索至少包含术语“数据库” 和“ sqlite”之一,并且还包含术语“库”的 文档。由于在运算符优先级方面存在差异,因此使用 增强的查询语法将对该查询产生不同的解释。 SELECT * FROM docs WHERE docs MATCH'sqlite OR database library';
FTS3和FTS4模块提供了三个特殊的SQL标量函数,它们对全文查询系统的开发人员可能有用:“ snippet”,“ offsets”和“ matchinfo”。“片段”和“偏移”功能的目的是允许用户识别所返回的文档中所查询术语的位置。“ matchinfo”功能向用户提供指标,这些指标可能有助于根据相关性对查询结果进行过滤或排序。
这三个特殊SQL标量函数的第一个参数必须是该函数所应用的FTS表的FTS隐藏列。该FTS隐藏的列是具有相同的名称作为FTS表本身的所有FTS表中找到一个自动生成的列。例如,给定一个名为“ mail”的FTS表:
SELECT offsets(mail)FROM mail WHERE mail MATCH <全文查询表达式>; SELECT snippet(mail)FROM mail WHERE mail MATCH <全文查询表达式>; 从邮件WHERE邮件匹配中选择matchinfo(mail)<全文查询表达式>;
这三个辅助功能仅在使用FTS表的全文本索引的SELECT语句中有用。如果在使用“按行查询查询”或“线性扫描”策略的SELECT中使用,则代码段和偏移量都将返回一个空字符串,而matchinfo函数将返回一个大小为零字节的blob值。
所有这三个辅助功能都从FTS查询表达式中提取出一组“可匹配的短语”以供使用。给定查询的可匹配短语集由表达式中的所有短语(包括未加引号的标记和标记前缀)组成,但以一元“-”运算符(标准语法)为前缀或属于以下子表达式的一部分的短语除外:用作NOT运算符的右侧操作数。
通过以下条件,FTS表中与查询表达式中可匹配短语之一匹配的每个令牌序列都称为“短语匹配”:
对于使用全文索引的SELECT查询,offsets()函数将返回一个文本值,该文本值包含一系列以空格分隔的整数。对于当前行的每个词组匹配中的每个术语,返回列表中有四个整数。每组四个整数的解释如下:
| 整数 | 解释 |
|---|---|
| 0 | 术语实例所在的列号(FTS表的最左列为0,下一个最左列为1,依此类推)。 |
| 1个 | 全文查询表达式中匹配术语的术语编号。查询表达式中的术语按照出现的顺序从0开始编号。 |
| 2个 | 列中匹配项的字节偏移量。 |
| 3 | 匹配项的大小(以字节为单位)。 |
以下块包含使用offsets函数的示例。
使用fts3(主题,正文)创建虚拟表邮件; INSERT INTO mail VALUES('hello world','此消息是一个hello world消息。'); INSERT INTO mail VALUES(“紧急:严重”,“此邮件被视为更严重的邮件”); -下面的查询返回单个行(因为它只有第一匹配 -条目表“邮件”由偏移函数返回的文本是 - “0 0 6 5 1 0 24 5”。 - -结果中的第一组四个整数表示列0- 包含字节偏移量为6的术语0(“ world”)的实例。术语instance-的 大小为5个字节。第二组四个整数显示: 匹配行的第 1列-包含术语0(“世界”)的实例,其字节偏移量为24。同样,术语instance的大小为5个字节。 从邮件WHERE邮件匹配“世界”中选择偏移量(邮件); -以下查询返回的结果也仅与表“ mail”中的第一行匹配。 -在这种情况下,返回的文本为“ 1 0 5 7 1 0 30 7”。 从邮件WHERE邮件匹配“消息”中选择偏移量(邮件); -以下查询与表“ mail”中的第二行匹配。它返回 -文本“ 1 0 28 7 1 1 36 4”。仅 识别出现“严重邮件” 和“邮件”的情况,它们是短语“严重邮件”的实例的一部分;在- “严重”和“邮件”等事件被忽略。 从邮件中选择偏移量(邮件)邮件匹配'“严重邮件”';
片段功能用于创建文档文本的格式化片段,以显示为全文查询结果报告的一部分。片段功能可以在1到6个参数之间传递,如下所示:
| 争论 | 默认值 | 描述 |
|---|---|---|
| 0 | 不适用 | 片段功能的第一个参数必须始终是 要查询的FTS表的FTS隐藏列,并从中获取片段。所述 FTS隐藏的列是具有相同名称为FTS表本身自动生成的列。 |
| 1个 | “ <b>” | “开始比赛”文本。 |
| 2个 | “ </ b>” | “结束匹配”文本。 |
| 3 | “ <b> ... </ b>” | “省略号”文本。 |
| 4 | -1 | FTS表的列号,用于从中提取返回的文本片段。列从零开始从左到右编号。负值表示可以从任何列中提取文本。 |
| 5 | -15 | 此整数参数的绝对值用作要包含在返回的文本值中的令牌的(大约)数目。允许的最大绝对值为64。在下面的讨论中 ,此参数的值称为N。 |
片段功能首先尝试查找由| N |组成的文本片段 当前行中包含至少一个短语匹配的标记,与在当前行中某处匹配的每个可匹配短语匹配,其中| N | 是传递到代码段函数的第六个参数的绝对值。如果存储在单列中的文本少于 | N | 标记,然后考虑整个列的值。文本片段不能跨多列。
如果可以找到这样的文本片段,则将其进行以下修改后返回:
如果可以找到多个这样的片段,则倾向于包含大量“额外”短语匹配的片段。可以将所选文本片段的开头向前或向后移动几个标记,以尝试将短语匹配集中到片段的中心。
假设N为正值,如果找不到包含与每个可匹配短语相对应的短语匹配的片段,则代码片段功能将尝试查找大约N / 2个标记的两个片段,它们之间的每个可匹配片段至少包含一个短语匹配与当前行匹配的词组。如果失败,则尝试查找每个N / 3令牌的三个碎片,最后找到四个N / 4令牌的碎片。如果找不到包含所需短语匹配的四个片段的集合,则选择提供最佳覆盖率的N / 4个令牌的四个片段。
如果N为负值,并且找不到包含所需短语匹配的单个片段,则片段功能将搜索| N |的两个片段。每个令牌,然后三个,然后四个。换句话说,如果N的指定值为负,则如果需要一个以上的片段来提供所需的词组匹配覆盖率,则不会减小片段的大小。
在找到M个片段之后(如上段所述,M在2到4之间),将它们按排序顺序连接在一起,并用“椭圆”文本将它们分开。在返回之前,对文本进行了前面列举的三个修改。
注意:在此示例块中,换行符和空格字符具有 被插入到插入FTS表中的文档中,并且预期 结果在SQL注释中描述。这样做只是为了提高可读性, 它们不会出现在实际的SQLite命令或输出中。 -创建并填充FTS表。 使用fts4()创建虚拟表文本; 插入文字值(' 在11月30日至12月1日期间,温度下降2-3oC。上部冷却,最低温度14-16oC 并在其他地方冷却,最低温度为17-20oC。在山顶上冷到很冷, 最低温度6-12oC。东北风15-30 km / hr。之后,温度 增加。东北风15-30 km / hr。 '); -以下查询返回文本值: -- “ <b> ... </ b>凉爽,最低温度17-20oC。<b>冷</ b>到非常 -<b>冷</ b>在山顶上,最低温度为6 <b> ... </ b>”。 -- SELECT snippet(text)from text WHERE text MATCH'cold'; -以下查询返回文本值: -- “ ...上部,[最低] [温度] 14-16oC,在其他地方冷却, -[最低] [温度] 17-20oC。 。” - SELECT snippet(text,'[',']','...')from text WHERE text MATCH'“ min * tem *”'
matchinfo函数返回一个blob值。如果在不使用全文本索引的查询(“按行ID查询”或“线性扫描”)中使用它,则该blob的大小为零字节。否则,blob包含零个或多个机器字节顺序的32位无符号整数。返回数组中整数的确切数量取决于查询和传递给matchinfo函数的第二个参数(如果有)的值。
使用一个或两个参数调用matchinfo函数。对于所有辅助功能,第一个参数必须是特殊的 FTS隐藏列。第二个参数(如果已指定)必须是仅由字符“ p”,“ c”,“ n”,“ a”,“ l”,“ s”,“ x”,“ y”组成的文本值和“ b”。如果未显式提供第二个参数,则默认为“ pcx”。第二个参数在下面称为“格式字符串”。
matchinfo格式字符串中的字符从左到右处理。格式字符串中的每个字符都会导致将一个或多个32位无符号整数值添加到返回的数组中。下表的“值”列包含每个支持的格式字符串字符附加到输出缓冲区的整数值的数量。在给定的公式中,cols是FTS表中的列数,而 短语是查询中可匹配的短语数。
| 特点 | 价值观 | 描述 |
|---|---|---|
| p | 1个 | 查询中可匹配短语的数量。 |
| C | 1个 | FTS表中用户定义的列数(即,不包括docid或FTS隐藏列)。 |
| X | 3 *的cols *短语 |
对于短语和表格列的每种不同组合,以下三个值:
hits_this_row = array [3 *(c + p * cols)+ 0]
hits_all_rows = array [3 *(c + p * cols)+1]
docs_with_hits = array [3 *(c + p * cols)+ 2]
|
| ÿ | cols *词组 |
对于短语和表格列的每种不同组合,列中出现的可用短语匹配数。通常,这与matchinfo'x'标志返回的每三个一组中的第一个值相同
。但是,对于属于与当前行不匹配的子表达式一部分的任何短语,“ y”标志报告的命中数为零。这对于包含作为OR运算符后代的AND运算符的表达式会有所不同。例如,考虑以下表达式:
a OR(b AND c)和文件: “ ac d”该matchinfo“X”标志将报告单发命中的短语“一”和“C”。但是,“ y”指令将“ c”的命中次数报告为零,因为它是与文档-(b AND c)不匹配的子表达式的一部分。对于不包含从OR运算符派生的AND运算符的查询,“ y”返回的结果值始终与“ x”返回的结果值相同。 整数值数组中的第一个值对应于表的最左列(列0)和查询中的第一个短语(短语0)。可以使用以下公式找到与其他列/短语组合相对应的值: hits_for_phrase_p_column_c =数组[c + p * cols]对于使用OR表达式的查询,或者使用LIMIT或返回许多行的查询,“ y” matchinfo选项可能比“ x”更快。 |
| b | ((cols + 31)/ 32) *词组 |
所述matchinfo“b”标记提供类似的信息给
matchinfo“y”的标志,但在一个更紧凑的形式。“ b”代替了准确的匹配数,而是为每个短语/列组合提供了一个布尔标志。如果该短语在该列中至少出现一次(即,如果“ y”的相应整数输出为非零),则设置相应的标志。否则清除。
如果表具有32列或更少的列,则为查询中的每个短语输出一个无符号整数。如果该短语在第0列中至少出现一次,则设置整数的最低有效位。如果该短语在第1列中出现一次或多次,则设置第二低位。 如果该表具有多于32列,则对于每一个额外的32列或其一部分,每个短语的输出中将添加一个额外的整数。对应于相同短语的整数会聚在一起。例如,如果查询一个包含45列的表以查询两个短语,则输出4个整数。第一个对应于短语0和表的第0-31列。第二个整数包含短语0和第32-44列的数据,依此类推。 例如,如果nCol是表中的列数,则确定短语p是否出现在列c中: p_is_in_c = array [p *((nCol + 31)/ 32)]&(1 <<(c%32)) |
| ñ | 1个 | FTS4表中的行数。该值仅在查询FTS4表时可用,而在FTS3中不可用。 |
| 一种 | 科尔斯 | 对于每一列,存储在该列中的文本值中的平均令牌数(考虑到FTS4表中的所有行)。该值仅在查询FTS4表时可用,而在FTS3中不可用。 |
| 升 | 科尔斯 | 对于每一列,以令牌形式存储在FTS4表的当前行中的值的长度。该值仅在查询FTS4表时可用,而在FTS3中不可用。并且仅在未将“ matchinfo = fts3”指令指定为用于创建FTS4表的“ CREATE VIRTUAL TABLE”语句的一部分的情况下。 |
| s | 科尔斯 | 对于每一列,短语的最长子序列的长度与该列值与查询文本共有的词组匹配。例如,如果表列包含文本“ abcde”且查询为“ ac“ d e”',则最长公共子序列的长度为2(短语“ c”,后跟短语“ d e”)。 |
例如:
-用两列创建并填充FTS4表: 使用fts4(a,b)创建虚拟表t1; 插入t1值('交易默认模型默认','非交易读取'); 插入t1值(“默认事务”,“存在这些语义”); 插入t1值('单个请求','默认数据'); -在以下查询中,未指定格式字符串,因此默认 为“ pcx”。因此,它将返回由单个blob组成的一行 -大小为80个字节(20个32位整数-1表示“ p”,1表示“ c”, -3 * 2 * 3表示“ x”)。如果在4个字节的每个块团块被解释 -如机字节顺序的无符号整数,其值将是: - - 3 2 1 3 2 0 1 1 1 2 2 0 1 1 0 0 0 1 1 1 - -行返回对应于插入到表t1的第二项。 -Blob中的前两个整数表明查询包含三个 短语,并且要查询的表具有两列。下一块 -三个整数描述列0(在此例中为“ a”列)和短语 -0(在此例中为“默认”列)。当前行在第0列中包含1个“默认”命中 -在 任何表行的 列-0中共包含3个“默认”命中。这3个匹配项分布在2个不同的行中。-- 下一组三个整数(0 1 1)与 表的第1列中的 “默认”匹配(此行中的0,所有行中的1,分布在-1行中)。 -- 从t1哪里t1匹配中选择SELECT matchinfo(t1)'默认事务“这些语义””; -此查询的格式字符串为“ ns”。因此,输出数组将 包含3个整数值-1表示“ n”,2表示“ s”。查询返回 -两行(表中的前两行匹配)。返回的值是: - - 3 1 1 - 3 2 0 - -为两行返回的matchinfo数组中的第一个值是3( -表的行数)。以下两个值是 每一列中词组匹配的最长公共子序列的长度-。 从t1处选择matchinfo(t1,'ns')t1匹配'默认事务';
matchinfo函数比代码片段或offsets函数快得多。这是因为需要同时执行代码段和偏移量才能从磁盘检索要分析的文档,而matchinfo所需的所有数据都可作为实现全文本所需的全文本索引相同部分的一部分获得查询本身。这意味着在以下两个查询中,第一个查询可能比第二个查询快一个数量级:
SELECT docid,matchinfo(tbl)从tbl那里tbl匹配<查询表达式>; SELECT docid,offsets(tbl)来自tbl,在哪里tbl MATCH <查询表达式>;
matchinfo函数提供计算概率“单词袋”相关性分数所需的所有信息,例如Okapi BM25 / BM25F,这些分数 可用于在全文搜索应用程序中对结果进行排序。本文档的附录A“搜索应用程序技巧”包含一个有效使用matchinfo()函数的示例。
从版本3.7.6(2011-04-12)开始,SQLite包含一个名为“ fts4aux”的新虚拟表模块,该模块可用于直接检查现有FTS表的全文索引。尽管名称如此,fts4aux在FTS3表上的工作效果与在FTS4表上一样好。Fts4aux表是只读的。修改fts4aux表内容的唯一方法是修改关联的FTS表的内容。fts4aux模块自动包含在所有包含FTS的内部版本中。
fts4aux虚拟表由一个或两个参数构成。与单个参数一起使用时,该参数是将用于访问的FTS表的非限定名称。要访问其他数据库中的表(例如,创建将访问MAIN数据库中的FTS3表的TEMP fts4aux表),请使用两个参数的形式并指定目标数据库的名称(例如:“ main”)在第一个参数中,将FTS3 / 4表的名称作为第二个参数。(为SQLite 3.7.17(2013-05-20)添加了fts4aux的两个参数形式,它将在以前的版本中引发错误。)例如:
-创建一个FTS4表 使用fts4(x,y)创建虚拟表ft; -创建fts4aux表以访问表“ ft”的全文本索引 使用fts4aux(ft)创建虚拟表ft_terms; -创建一个TEMP fts4aux表,以访问“主”中的“ ft”表 使用fts4aux(main,ft)创建虚拟表temp.ft_terms_2;
对于FTS表中存在的每个术语,fts4aux表中有2到N + 1行,其中N是相关FTS表中用户定义的列数。fts4aux表始终从左到右具有相同的四列,如下所示:
| 栏名 | 栏目内容 |
|---|---|
| 学期 | 包含此行的术语文本。 |
| 关口 | 该列可以包含文本值“ *”(即单个字符U + 002a)或0到N-1之间的整数,其中N再次是相应FTS表中用户定义的列数。 |
| 单据 |
此列始终包含大于零的整数值。
如果“ col”列包含值“ *”,则此列包含FTS表的行数,该行至少包含该术语的一个实例(在任何列中)。如果col包含整数值,则此列包含FTS表的行数,该行包含col值所标识的列中至少一个术语的实例。像往常一样,FTS表的列从零开始从左到右编号。 |
| 发生 |
此列还始终包含一个大于零的整数值。
如果“ col”列包含值“ *”,则此列包含FTS表的所有行中(在任何列中)该术语的实例总数。否则,如果col包含整数值,则此列包含由col值标识的FTS表列中显示的术语的实例总数。 |
| languageid (隐藏) |
此列确定使用哪种languageid从FTS3 / 4表中提取词汇。
languageid的默认值为0。如果在WHERE子句约束中指定了替代语言,则使用该替代语言代替0。每个查询只能有一个languageid。换句话说,WHERE子句不能在languageid上包含范围约束或IN运算符。 |
例如,使用上面创建的表:
插入ft(x,y)值('Apple banana','Cherry'); 插入ft(x,y)值('香蕉日期日期','樱桃'); 插入ft(x,y)值('Cherry Elderberry','Elderberry'); -下面的查询返回此数据: - -苹果| * | 1 | 1- 苹果| 0 | 1 | 1- 香蕉| * | 2 | 2- 香蕉| 0 | 2 | 2- 樱桃| * | 3 | 3- 樱桃| 0 | 1 | 1- 樱桃| 1 | 2 | 2- 日期| * | 1 | 2- 日期| 0 | 1 | 2- 接骨木| * | 1 | 2- 接骨木| 0 | 1 | 1- 接骨木| 1 | 1 | 1 - SELECT术语,列,文档,来自ft_terms的出现;
在该示例中,“ term”列中的值均为小写字母,即使它们以混合大小写形式插入表“ ft”中也是如此。这是因为fts4aux表包含由分词器从文档文本中提取的术语。在这种情况下,由于表“ ft”使用 简单的分词器,因此这意味着所有术语均已折叠为小写。此外,(例如)不存在将“ term”列设置为“ apple”且将“ col”列设置为1的行。由于在第1列中没有术语“ apple”的实例,因此fts4aux表。
在事务期间,仅当提交事务时,写入FTS表的某些数据才可以缓存在内存中并写入数据库。但是,fts4aux模块的实现只能从数据库中读取数据。实际上,这意味着,如果从已修改了相关FTS表的事务中查询fts4aux表,则查询结果很可能仅反映所做更改的子集(可能为空)。
如果“ CREATE VIRTUAL TABLE”语句指定模块FTS4(而不是FTS3),则类似于“ tokenize = *”选项的特殊指令-FTS4选项也可能出现在列名的位置。FTS4选项由选项名称,后跟“ =”字符和后跟选项值组成。选项值可以有选择地用单引号或双引号引起来,嵌入式引号字符的转义方式与SQL文字相同。“ =”字符的两边可能没有空格。例如,要创建一个将选项“ matchinfo”的值设置为“ fts3”的FTS4表:
-创建占用空间较小的FTS4表。 使用fts4(作者,文档,matchinfo = fts3)创建虚拟表文件;
FTS4当前支持以下选项:
| 选项 | 解释 |
|---|---|
| 压缩 | compress选项用于指定compress函数。指定压缩功能而不指定解压缩功能是错误的。有关详情,请参见下文。 |
| 内容 | 内容允许将要索引的文本存储在与FTS4表不同的单独表中,甚至可以存储在SQLite之外。 |
| 语言 | languageid选项使FTS4表具有一个附加的隐藏整数列,该列标识每行中包含的文本的语言。使用languageid选项允许同一FTS4表以多种语言或脚本保存文本,每种语言或脚本具有不同的标记符规则,并且可以独立于其他语言查询每种语言。 |
| 比赛信息 | 当设置为值“ fts3”时,matchinfo选项会减少FTS4存储的信息量,结果是matchinfo()的“ l”选项 不再可用。 |
| 未索引 | 此选项用于指定未为其索引数据的列的名称。MATCH查询不匹配未索引的列中存储的值。辅助功能也无法识别它们。单个CREATE VIRTUAL TABLE语句可以具有任意数量的未索引选项。 |
| 命令 | 可以将“ order”选项设置为“ DESC”或“ ASC”(大写或小写)。如果将其设置为“ DESC”,则FTS4以按docid降序优化返回结果的方式存储其数据。如果将其设置为“ ASC”(默认值),那么将优化数据结构以按docid升序返回结果。换句话说,如果针对FTS4表运行的许多查询都使用“ ORDER BY docid DESC”,则将“ order = desc”选项添加到CREATE VIRTUAL TABLE语句可能会提高性能。 |
| 字首 | 可以将此选项设置为以逗号分隔的正非零整数列表。对于列表中的每个整数N ,在使用UTF-8进行编码时,都会在数据库文件中创建一个单独的索引以优化前缀查询,其中查询项的长度为N个字节,不包括'*'字符。有关详情,请参见下文。 |
| 解压 | 此选项用于指定解压缩功能。在不指定压缩功能的情况下指定解压缩功能是错误的。有关详情,请参见下文。 |
使用FTS4时,指定包含“ =”字符且既不是“ tokenize = *”规范又不是公认的FTS4选项的列名是错误的。对于FTS3,无法识别的伪指令中的第一个标记被解释为列名。类似地,在使用FTS4时,在单个表声明中指定多个“ tokenize = *”指令是错误的,而第二个及后续的“ tokenize = *”指令被FTS3解释为列名。例如:
- 一个错误。FTS4无法识别指令“ xyz = abc”。 使用fts4(作者,文档,xyz = abc)创建虚拟表文件; -创建一个包含三列的FTS3表-“作者”,“文档” 和“ xyz”。 使用fts3(作者,文档,xyz = abc)创建虚拟表文件; - 一个错误。FTS4不允许多个tokenize = *指令 使用fts4(tokenize = porter,tokenize = simple)创建虚拟表文件; -用一个名为“ tokenize”的列创建一个FTS3表。本 -表使用了“搬运工”标记生成器。 使用fts3(tokenize = porter,tokenize = simple)创建虚拟表文件; - 一个错误。无法创建包含名为“ tokenize”的两列的表。 使用fts3(tokenize = porter,tokenize = simple,tokenize = icu)创建虚拟表文件;
压缩和解压缩选项允许FTS4内容以压缩形式存储在数据库中。这两个选项都应设置为使用sqlite3_create_function()注册的SQL标量函数的名称,该函数 接受单个参数。
compress函数应返回作为参数传递给它的值的压缩版本。每次将数据写入FTS4表时,每个列值都传递给compress函数,结果值存储在数据库中。compress函数可以返回任何类型的SQLite值(blob,text,real,integer或null)。
解压缩功能应解压缩先前由compress函数压缩的数据。换句话说,对于所有SQLite值X,uncompress(compress(X))等于X应该是正确的。当通过FTS4从数据库读取通过compress函数压缩的数据时,会将其传递给uncompress函数在使用之前。
如果指定的压缩或解压缩功能不存在,则可能仍会创建该表。直到读取(如果不存在uncompress函数)或写入(如果不存在compress函数)FTS4表,才不会返回错误。
-创建一个FTS4表以压缩形式存储数据。这 -假设标量函数zip()和unzip()已(或 将被)添加到数据库句柄。 使用fts4创建虚拟表文件(作者,文档,compress = zip,uncompress = unzip);
在实现压缩和解压缩功能时,重要的是要注意数据类型。具体来说,当用户从压缩的FTS表中读取值时,FTS返回的值与uncompress函数返回的值完全相同,包括数据类型。如果该数据类型与传递给compress函数的原始值的数据类型不同(例如,当最初传递TEXT时uncompress函数返回BLOB),则用户查询可能无法按预期运行。
content选项允许FTS4放弃存储被索引的文本。content选项可以以两种方式使用:
已建立索引的文档根本不存储在SQLite数据库中(“无内容” FTS4表),或者
已建立索引的文档存储在用户创建和管理的数据库表中(“外部内容” FTS4表)。
由于索引文档本身通常比全文索引大得多,因此content选项可用于节省大量空间。
为了创建一个根本不存储索引文档副本的FTS4表,应该将content选项设置为空字符串。例如,以下SQL使用三列“ a”,“ b”和“ c”创建这样的FTS4表:
使用fts4(content =“”,a,b,c)创建虚拟表t1;
可以使用INSERT语句将数据插入到这样的FTS4表中。但是,与普通的FTS4表不同,用户必须提供一个显式的整数docid值。例如:
-这条语句是可以的: 插入t1(docid,a,b,c)VALUES(1,'ab c','de f','gh i'); -此语句导致错误,因为未提供docid值: 插入t1(a,b,c)VALUES('jk l','mn o','pq r');
无法更新或删除存储在无内容的FTS4表中的行。尝试这样做是错误的。
无内容的FTS4表还支持SELECT语句。但是,尝试检索除docid列以外的任何表列的值都是错误的。可以使用辅助功能matchinfo(),但不能使用snippet()和offsets()。例如:
-以下语句是可以的: 从t1的t1匹配'xxx'中选择docid; 从t1匹配xxx处选择docid; 从t1的t1匹配'xxx'中选择matchinfo(t1); -以下语句均会导致错误,因为 除docid之外,还需要对列的值进行求值。 选择*从t1; 从t1的t1匹配'xxx'中选择a,b; 从t1中选择docid,例如“ xxx%”; 从t1的t1匹配'xxx'中选择snippet(t1);
与尝试检索除docid以外的列值有关的错误是在sqlite3_step()中发生的运行时错误。在某些情况下,例如,如果SELECT查询中的MATCH表达式匹配零行,则即使语句确实引用了docid以外的列值,也可能根本没有错误。
“外部内容” FTS4表类似于无内容表,不同之处在于,如果对查询的评估需要除docid以外的列的值,则FTS4尝试从指定的表(或视图或虚拟表)中检索该值。用户(以下称为“内容表”)。FTS4模块从不写入内容表,并且写入内容表不影响全文本索引。用户有责任确保内容表和全文索引一致。
通过将content选项设置为表(或视图或虚拟表)的名称来创建外部内容FTS4表,该表名称可由FTS4查询以在需要时检索列值。如果指定的表不存在,则外部内容表的行为与无内容表相同。例如:
创建表t2(id整数主键,a,b,c); 使用fts4(content =“ t2”,a,c)创建虚拟表t3;
假设被提名表确实存在,那么其列必须与为FTS表定义的列相同或超集。外部表还必须与FTS表位于同一数据库文件中。换句话说,外部表不能位于使用ATTACH连接的其他数据库文件 中,FTS表和外部内容中的一个不能位于TEMP数据库中,而另一个则位于诸如MAIN之类的持久数据库文件中。
当用户在FTS表上查询时需要除docid以外的列值时,FTS尝试从内容表中该行的相应列中读取所请求的值,且rowid值等于当前FTS docid。仅查询在FTS / 34表声明中重复的内容表列的子集-要从任何其他列中检索值,必须直接查询内容表。或者,如果在内容表中找不到这样的行,那么将使用NULL值。例如:
创建表t2(id整数主键,a,b,c); 使用fts4(content =“ t2”,b,c)创建虚拟表t3; 插入t2值(2,'a b','cd d','e f'); 插入t2值(3,'g h','i j','k l'); 插入t3(docid,b,c)SELECT id,b,c FROM t2; -以下查询返回包含两列的一行 -文本值“ i j”和“ k l”。 -- -查询使用全文本索引来发现MATCH -term与docid = 3的行匹配。然后检索值 -内容表中rowid = 3的行中的b和c列 - 返回。 -- 选择*从t3到t3匹配'k'; -在UPDATE之后,查询仍然返回单行,这 -包含文本值“ xxx”和“ yyy”的时间。这是因为 -全文索引仍指示docid = 3的行匹配 -FTS4查询“ k”,即使文档存储在内容中 -表已被修改。 -- 更新t2 SET b ='xxx',c ='yyy'WHERE rowid = 3; 选择*从t3到t3匹配'k'; -在下面的DELETE之后,查询返回一行,其中包含两行 -NULL值。因为无法找到FTS,所以返回NULL值 -内容表中rowid = 3的行。 -- 从t2删除; 选择*从t3到t3匹配'k';
从外部内容FTS4表中删除行时,FTS4需要检索从内容表中删除的行的列值。这样,FTS4可以为已删除行中出现的每个令牌更新全文索引条目,以指示该行已被删除。如果找不到内容表行,或者如果它包含与FTS索引的内容不一致的值,则结果可能很难预测。FTS索引可能会保留包含与已删除行相对应的条目,这可能导致后续的SELECT查询返回看似无意义的结果。在更新行时也是如此,因为在内部UPDATE与后跟INSERT的DELETE相同。
这意味着为了使FTS与外部内容表保持同步,必须先将任何UPDATE或DELETE操作应用于FTS表,然后再应用于外部内容表。例如:
创建表t1_real(id INTEGER PRIMARY KEY,a,b,c,d); 使用fts4(content =“ t1_real”,b,c)创建虚拟表t1_fts; -这有效。从FTS表中删除该行时,FTS检索 -rowid = 123的行并将其标记化,以确定条目 -必须从全文索引中删除。 -- 从t1_fts删除,其中rowid = 123; 从t1_real删除WHERE rowid = 123; –这不起作用。在FTS表更新时,该行 -已从基础内容表中删除。因此 -FTS无法确定要从FTS索引中删除的条目,并且 -因此索引和内容表不同步。 -- 从t1_real删除WHERE rowid = 123; 从t1_fts删除,其中rowid = 123;
某些用户可能希望使用数据库触发器来使全文索引相对于存储在内容表中的文档集保持最新,而不是分别写入全文索引和内容表。例如,使用先前示例中的表:
在t2开始更新之前创建触发器t2_bu 从t3删除docid = old.rowid; 结尾; 在t2开始删除之前创建触发t2_bd 从t3删除docid = old.rowid; 结尾; 在t2开始更新之后创建触发器t2_au 插入t3(docid,b,c)值(new.rowid,new.b,new.c); 结尾; 在t2开始插入后创建t2_ai触发器 插入t3(docid,b,c)值(new.rowid,new.b,new.c); 结尾;
必须先触发DELETE触发器,然后在内容表上进行实际的删除。这样,FTS4仍可以检索原始值以更新全文本索引。并且在插入新行之后必须触发INSERT触发器,以处理在系统中自动分配rowid的情况。出于相同的原因,必须将UPDATE触发器分为两部分,一部分在更新内容表之前触发,另一部分在更新内容表之后触发。
该FTS4“重建”命令 删除整个全文索引并重建它基于当前的一组中的内容表的文档。再次假设“ t3”是外部内容FTS4表的名称,那么rebuild命令如下所示:
插入t3(t3)值('rebuild');
该命令还可以与普通FTS4表一起使用,例如,如果令牌化程序的实现发生更改。尝试重建由无内容的FTS4表维护的全文索引是错误的,因为没有内容可用于重建。
当languageid选项存在时,它指定添加到FTS4表的另一个隐藏列的名称,该列用于指定存储在FTS4表的每一行中的语言。languageid隐藏列的名称必须与FTS4表中的所有其他列名称不同。例子:
使用fts4(x,y,languageid =“ lid”)创建虚拟表t1
languageid列的默认值为0。任何插入languageidid列的值都将转换为32位(不是64)有符号整数。
默认情况下,FTS查询(使用MATCH运算符的查询)仅考虑将languageid列设置为0的行。要查询具有其他languageid值的行,格式为“
选择*从t1到t1匹配'abc'且lid = 5;
单个FTS查询不可能返回具有不同languageid值的行。未添加使用其他运算符(例如lid!= 5或lid <= 5)的WHERE子句的结果。
如果将content选项与languageid选项一起使用,则命名的languageid列必须存在于content =表中(遵循通常的规则-如果查询从不需要读取内容表,则此限制不适用)。
使用languageid选项时,SQLite在创建对象后立即在sqlite3_tokenizer_module对象上调用xLanguageid(),以便传递令牌化程序应使用的语言ID。对于任何单个标记生成器对象,xLanguageid()方法都不会被调用多次。不同语言可能被不同地标记的事实是没有一个FTS查询可以返回具有不同languageid值的行的原因之一。
matchinfo选项只能设置为值“ fts3”。尝试将matchinfo设置为除“ fts3”以外的任何其他内容是错误的。如果指定了此选项,则将省略FTS4存储的一些额外信息。这将减少FTS4表占用的磁盘空间量,直到与等效的FTS3表将使用的磁盘空间量几乎相同为止,而且还意味着通过将'l'标志传递给matchinfo()来访问数据。功能不可用。
通常,FTS模块在表的所有列中维护所有术语的倒排索引。此选项用于指定不应将条目添加到索引的列的名称。可以使用多个“未索引”选项来指定应从索引中省略多个列。例如:
-创建一个FTS4表,仅对c2和c4列的内容 进行标记并添加到倒排索引中。 使用fts4(c1,c2,c3,c4,notindexed = c1,notindexed = c3)创建虚拟表t1;
存储在未索引列中的值不符合匹配MATCH运算符的条件。它们不影响offsets()或matchinfo()辅助函数的结果。snippet()函数也不会基于未索引列中存储的值返回任何代码段。
FTS4前缀选项使FTS以始终索引完整术语的相同方式来索引指定长度的术语前缀。必须将prefix选项设置为以逗号分隔的正非零整数列表。对于列表中的每个值N,索引长度为N个字节的前缀(使用UTF-8编码时)。FTS4使用术语前缀索引来加速 前缀查询。当然,代价是索引术语前缀和完整术语会增加数据库大小,并减慢FTS4表上的写操作。
在两种情况下, 可以使用前缀索引来优化前缀查询。如果查询的前缀为N个字节,则使用“ prefix = N”创建的前缀索引将提供最佳的优化。或者,如果没有“ prefix = N”索引可用,则可以改用“ prefix = N + 1”索引。使用“ prefix = N + 1”索引比“ prefix = N”索引效率低,但比根本没有前缀索引要好。
-创建带有索引的FTS4表以优化2和4字节前缀查询。 使用fts4(c1,c2,prefix =“ 2,4”)创建虚拟表t1; -以下两个查询都使用前缀索引进行了优化。 选择*从t1到t1匹配'ab *'; 选择*从t1到t1匹配'abcd *'; -以下两个查询都使用前缀 -索引 进行了部分优化。该优化的效果不如上面的查询那么明显,但是仍然比没有前缀索引有所改进。 选择*从t1到t1匹配'a *'; 选择*从t1到t1匹配'abc *';
特殊的INSERT操作可用于向FTS3和FTS4表发出命令。每个FTS3和FTS4都有一个隐藏的只读列,该列与表本身的名称相同。将此隐藏列中的INSERT解释为对FTS3 / 4表的命令。对于名称为“ xyz”的表,支持以下命令:
插入xyz(xyz)VALUES('optimize');
插入xyz(xyz)VALUES('rebuild');
插入xyz(xyz)值('integrity-check');
插入xyz(xyz)VALUES('merge = X,Y');
插入xyz(xyz)VALUES('automerge = N');
“优化”命令使FTS3 / 4将所有其反向索引的b树合并为一个完整的大b树。由于要搜索的b树较少,因此进行优化将使后续查询运行更快,并且可以通过合并冗余条目来减少磁盘使用。但是,对于较大的FTS表,运行优化可能与运行VACUUM一样昂贵。最优化命令本质上必须读取和写入整个FTS表,从而导致大量事务。
在批处理模式操作中,最初使用大量INSERT操作建立FTS表,然后在不作进一步更改的情况下重复查询,通常最好在最后一次INSERT之后和第一个查询之前运行“优化”。
“重建”命令使SQLite放弃整个FTS3 / 4表,然后从原始文本重新重建它。该概念类似于REINDEX,只不过它适用于FTS3 / 4表而不是普通索引。
每当自定义标记生成器的实现发生更改时,都应运行“ rebuild”命令,以便可以重新标记所有内容。在对原始内容表进行更改之后,使用FTS4内容选项时,“重建”命令也很有用 。
“完整性检查”命令使SQLite通过将反向索引与原始内容进行比较来读取并验证FTS3 / 4表中所有反向索引的准确性。如果所有倒序索引都正常,则“ integrity-check”命令将以静默方式成功执行,但是如果发现任何问题,则将失败并显示SQLITE_CORRUPT错误。
“ integrity-check”命令在概念上与PRAGMA integrity_check相似 。在工作系统中,“完整性命令”应该总是成功的。完整性检查失败的可能原因包括:
“ merge = X,Y”命令(其中X和Y是整数)使SQLite进行有限的工作,以将FTS3 / 4表的各种反向索引b树合并到一个大b树中。X值是要合并的“块”的目标数量,Y值是在将合并应用于该级别之前所需级别上b树分支的最小数量。Y的值应在2到16之间,建议值为8。X的值可以是任何正整数,但是建议使用100到300的数量级。
当FTS表在同一级别上累积16个b树段时,对该表的下一个INSERT将导致所有16个段在下一个较高级别上合并为单个b树段。这些级别合并的结果是,进入FTS表的大多数INSERT速度非常快,占用的内存最少,但是由于需要进行合并,偶尔的INSERT速度很慢并且会生成大量事务。这导致INSERT的“尖峰”性能。
为了避免尖锐的INSERT性能,应用程序可以定期(可能在空闲线程或空闲进程中)运行“ merge = X,Y”命令,以确保FTS表在同一级别上永远不会累积太多的b树片段。通过每插入几千个文档后运行“ merge = X,Y”,通常可以避免INSERT性能峰值,并且可以最大化FTS3 / 4的性能。每个“ merge = X,Y”命令将在单独的事务中运行(当然,除非使用BEGIN ... COMMIT将它们分组在一起)。通过为X选择一个介于100到300之间的值,可以使交易保持较小状态。 在每个“ merge = X,Y”命令之前和之后,并在差值降至2以下时停止循环。
“ automerge = N”命令(其中N是0到15之间的整数)用于配置FTS3 / 4表的“ automerge”参数,该参数控制自动递增的倒排索引合并。新表的默认自动合并值为0,表示完全禁用自动增量合并。如果使用“ automerge = N”命令修改了automerge参数的值,则新的参数值将永久存储在数据库中,并由所有随后建立的数据库连接使用。
将automerge参数设置为非零值可启用自动增量合并。这导致SQLite在每个INSERT操作之后进行少量的反向索引合并。对执行的合并量进行了设计,以使FTS3 / 4表永远不会达到在同一级别具有16个段的位置,因此必须进行大合并才能完成插入。换句话说,自动增量合并旨在防止尖锐的INSERT性能。
自动增量合并的缺点是,由于必须花费额外的时间来进行增量合并,因此它会使FTS3 / 4表上的每个INSERT,UPDATE和DELETE操作的运行速度都变慢。为了获得最佳性能,建议应用程序禁用自动增量合并,而应在空闲过程中使用 “ merge”命令来保持反向索引很好地合并。但是,如果应用程序的结构不容易允许空闲进程,则使用自动增量合并是一种非常合理的后备解决方案。
automerge参数的实际值确定通过自动反向索引合并同时合并的索引段的数量。如果将该值设置为N,则系统将等待直到单个级别上至少存在N个段,然后才开始逐步合并它们。设置较低的N值可以使段合并更快,这可以加快全文查询的速度,并且如果工作负载包含UPDATE或DELETE操作以及INSERT,则可以减少全文索引占用的磁盘空间。但是,这也会增加写入磁盘的数据量。
对于工作负载包含很少的UPDATE或DELETE操作的情况下的常规使用,自动合并的最佳选择是8。如果工作负载包含许多UPDATE或DELETE命令,或者如果考虑查询速度,则将自动合并减小为2可能是有利的。 。
出于向后兼容性的原因,“ automerge = 1”命令将automerge参数设置为8,而不是1(无论如何,值1都毫无意义,因为合并来自单个段的数据是无操作的)。
FTS标记器是用于从文档或基本FTS全文查询中提取术语的一组规则。
除非在用于创建FTS表的CREATE VIRTUAL TABLE语句中指定了特定的标记器,否则将使用默认的标记器“ simple”。简单令牌生成器根据以下规则从文档或基本FTS全文查询中提取令牌:
术语是合格字符的连续序列,其中合格字符是所有字母数字字符,并且所有Unicode码点值大于或等于128的字符。将文档拆分为术语时,所有其他字符将被丢弃。它们的唯一作用是分隔相邻的术语。
作为标记化过程的一部分,ASCII范围内的所有大写字符(Unicode代码点少于128个)都将转换为它们的小写等效项。因此,使用简单令牌生成器时,全文查询不区分大小写。
例如,当包含文本“立即,它们非常沮丧”的文档时,从文档中提取并添加到全文索引的术语按顺序依次为“现在它们非常沮丧”。这样的文档将与诸如“ MATCH'Frustrated'”之类的全文查询匹配,因为简单的分词器会在搜索全文索引之前将查询中的术语转换为小写。
与“简单”标记器一样,FTS源代码还具有使用Porter Stemming算法的标记器。。该标记器使用相同的规则将输入文档分为多个术语,包括将所有术语折叠成小写,还使用Porter Stemming算法将相关的英语单词还原为一个通用词根。例如,使用与上段相同的输入文档,搬运程序令牌生成器将提取以下令牌:“现在,正确地挫败”。即使这些术语中的某些甚至不是英语单词,在某些情况下,使用它们来构建全文本索引也比简单令牌生成器产生的更清晰的输出更有用。使用搬运程序令牌生成器,文档不仅匹配诸如“ MATCH'Frustrated'”之类的全文查询,还匹配诸如“ MATCH'Frustration'”之类的查询,称为术语“ Frustration” 通过Porter stemmer算法将其减少为“受挫”-就像“受挫”一样。因此,在使用搬运程序令牌生成器时,FTS不仅能够找到查询词的完全匹配项,而且还能找到与类似英语术语的匹配项。有关Porter Stemmer算法的更多信息,请参考上面链接的页面。
举例说明“简单”和“端口”标记符之间的区别的示例:
-使用简单的令牌生成器创建表。将文档插入其中。 使用fts3(tokenize = simple)创建虚拟表简单 插入简单的值(“现在他们很沮丧”); -以下两个查询中的第一个与存储在 “简单”表中的文档匹配。第二个没有。 选择*从简单的地方,简单的比赛“沮丧”; SELECT *从简单的WHERE简单匹配'Frustration'; -使用搬运工令牌生成器创建表。将相同的文档插入其中 使用fts3(tokenize = porter)创建虚拟表搬运程序; INSERT INTO porter VALUES(“现在他们很沮丧”); -以下两个查询均与表“ porter”中存储的文档匹配。 SELECT * FROM搬运工WHERE搬运工MATCH'Frustrated'; 选择*从搬运工WHERE搬运工MATCH'Frustration';
如果使用定义的SQLITE_ENABLE_ICU预处理器符号编译此扩展,则存在使用ICU库实现的名为“ icu”的内置标记器。传递给此令牌生成器的xCreate()方法(请参阅fts3_tokenizer.h)的第一个参数可以是ICU语言环境标识符。例如,在土耳其使用的土耳其语为“ tr_TR”,在澳大利亚使用的英语为“ en_AU”。例如:
使用fts3(text,tokenize = icu th_TH)创建虚拟表thai_text
ICU令牌生成器的实现非常简单。它根据用于查找单词边界的ICU规则拆分输入文本,并丢弃所有完全由空格组成的标记。这可能适用于某些语言环境中的某些应用程序,但不是全部。如果需要进行更复杂的处理(例如,实施词干或丢弃标点符号),则可以通过创建将ICU令牌生成器用作其实现的一部分的令牌生成器实现来完成。
从SQLite版本3.7.13 (2012-06-11)开始可以使用“ unicode61”令牌生成器。Unicode61的工作原理与“简单”非常相似,不同之处在于,它按照Unicode版本6.1中的规则进行简单的unicase大小写折叠,并且可以识别unicode空间和标点符号,并使用它们来分隔标记。简单的令牌生成器仅对ASCII字符进行大小写折叠,并且仅将ASCII空格和标点符号识别为令牌分隔符。
默认情况下,“ unicode61”尝试从拉丁字母字符中删除变音符号。可以通过添加令牌生成器参数“ remove_diacritics = 0”来覆盖此行为。例如:
-创建表以从拉丁字母字符中删除所有变音符号 -作为标记化的一部分。 使用fts4(tokenize = unicode61)创建虚拟表txt1; 使用fts4(tokenize = unicode61“ remove_diacritics = 2”)创建虚拟表txt2; -创建一个不会从拉丁文字中删除变音符号的表 -字符化作为标记化的一部分。 使用fts4(tokenize = unicode61“ remove_diacritics = 0”)创建虚拟表txt3;
remove_diacritics选项可以设置为“ 0”,“ 1”或“ 2”。默认值为“ 1”。如果将其设置为“ 1”或“ 2”,则如上所述,从拉丁字母字符中删除变音符号。但是,如果将其设置为“ 1”,则在使用单个unicode码点表示一个带有多个变音符号的字符的情况非常少见的情况下,不删除变音符号。例如,变音符号没有从代码点0x1ED9中删除(“带有小圆点和下面的点的拉丁文小写字母O”)。从技术上讲,这是一个错误,但是如果不产生向后兼容性问题就无法修复。如果此选项设置为“ 2”,则将从所有拉丁字符中正确删除变音符号。
还可以自定义unicode61视为分隔符的代码点集。“ separators =”选项可用于指定一个或多个额外字符,应将其视为分隔符,而“ tokenchars =”选项可用于指定一个或多个额外字符,而应将其视为标记的一部分作为分隔符。例如:
-创建一个使用unicode61标记程序的表,但将其视为“”。 -和“ =”字符作为标记的一部分,大写“ X”字符作为 -用作分隔符。 使用fts4(tokenize = unicode61“ tokenchars =。=”“ separators = X”)创建虚拟表txt3; -创建一个将空格字符(代码点32)视为 -令牌字符的表 使用fts4(tokenize = unicode61“ tokenchars =”)创建虚拟表txt4;
如果默认情况下将作为“ tokenchars =”的参数的一部分指定的字符视为令牌字符,则将其忽略。即使以前的“ separators =“选项将其标记为分隔符,也是如此。同样,如果默认情况下将指定为“ separators =“选项的一部分的字符视为分隔符,则将其忽略。如果指定了多个“ tokenchars =”或“ separators =”选项,则将全部处理。例如:
-创建一个使用unicode61标记程序的表,但将其视为“”。
-和“ =”字符作为标记的一部分,大写“ X”字符作为
-用作分隔符。这两个“ tokenchars =”选项都已处理
-“ separators =”选项忽略了“”。传递给它,为“。” 是
-默认分隔符,即使它已被标记为一个令牌
-字符由早先的“tokenchars =”选项。
使用fts4创建虚拟表txt5(
tokenize = unicode61“ tokenchars =”。“分隔符= X”。“ tokenchars ==”
);
传递给“ tokenchars =”或“ separators =”选项的参数区分大小写。在上面的示例中,指定“ X”为分隔符不会影响处理“ x”的方式。
除了提供内置的“简单”,“ porter”以及(可能)“ icu”和“ unicode61”令牌生成器之外,FTS还为应用程序提供了一个接口,用于实现和注册用C编写的自定义令牌生成器。该接口用于创建新的令牌生成器。令牌生成器在fts3_tokenizer.h源文件中定义和描述。
注册新的FTS令牌生成器类似于使用SQLite注册新的虚拟表模块。用户将指针传递给一个结构,该结构包含指向构成新令牌生成器类型的实现的各种回调函数的指针。对于令牌生成器,该结构(在fts3_tokenizer.h中定义)称为“ sqlite3_tokenizer_module”。
FTS不会公开用户调用的C函数以向数据库句柄注册新的令牌生成器类型。而是必须将指针编码为SQL Blob值,并通过评估特殊的标量函数“ fts3_tokenizer()”,通过SQL引擎将其传递给FTS。可以使用一个或两个参数来调用fts3_tokenizer()函数,如下所示:
选择fts3_tokenizer(<tokenizer-name>); 选择fts3_tokenizer(<tokenizer-name>,<sqlite3_tokenizer_module ptr>);
其中<tokenizer-name>是使用sqlite3_bind_text()绑定字符串的参数,其中 字符串标识令牌生成器,而<sqlite3_tokenizer_module ptr>是使用sqlite3_bind_blob()绑定BLOB的参数,其中BLOB的值是a指向sqlite3_tokenizer_module结构的指针。如果存在第二个参数,则将其注册为令牌生成器<tokenizer-name>并返回其副本。如果仅传递一个参数,则返回指向当前注册为<tokenizer-name>的令牌生成器实现的指针,并将其编码为Blob。或者,如果不存在这样的令牌生成器,则会引发SQL异常(错误)。
在SQLite版本3.11.0(2016-02-15)之前,fts3_tokenzer()的参数可以是文字字符串或BLOB。它们不必绑定参数。但这可能会在SQL注入事件中导致安全问题。因此,默认情况下现在禁用旧行为。但是,可以通过调用sqlite3_db_config(db,SQLITE_DBCONFIG_ENABLE_FTS3_TOKENIZER,1,0)来启用旧的旧行为,以在真正需要它的应用程序中实现向后兼容性 。
以下块包含从C代码调用fts3_tokenizer()函数的示例:
/ *
**向FTS3或FTS4注册令牌生成器实现。
* /
int registerTokenizer(
sqlite3 * db,
char * zName,
const sqlite3_tokenizer_module * p
){
int rc;
sqlite3_stmt * pStmt;
const char * zSql =“ SELECT fts3_tokenizer(?1,?2)”;
rc = sqlite3_prepare_v2(db,zSql,-1,&pStmt,0);
if(rc!= SQLITE_OK){
返回rc;
}
sqlite3_bind_text(pStmt,1,zName,-1,SQLITE_STATIC);
sqlite3_bind_blob(pStmt,2,&p,sizeof(p),SQLITE_STATIC);
sqlite3_step(pStmt);
返回sqlite3_finalize(pStmt);
}
/ *
**查询FTS以获取名为zName的令牌生成器实现。
* /
int queryTokenizer(
sqlite3 * db,
char * zName,
const sqlite3_tokenizer_module ** pp
){
int rc;
sqlite3_stmt * pStmt;
const char * zSql =“ SELECT fts3_tokenizer(?)”;
* pp = 0;
rc = sqlite3_prepare_v2(db,zSql,-1,&pStmt,0);
if(rc!= SQLITE_OK){
返回rc;
}
sqlite3_bind_text(pStmt,1,zName,-1,SQLITE_STATIC);
if(SQLITE_ROW == sqlite3_step(pStmt)){
if(sqlite3_column_type(pStmt,0)== SQLITE_BLOB){
memcpy(pp,sqlite3_column_blob(pStmt,0),sizeof(* pp));
}
}
返回sqlite3_finalize(pStmt);
}
“ fts3tokenize”虚拟表可用于直接访问任何令牌生成器。以下SQL演示了如何创建fts3tokenize虚拟表的实例:
使用fts3tokenize('porter')创建虚拟表tok1;
当然,在示例中,应使用所需标记器的名称代替“ porter”。如果令牌生成器需要一个或多个参数,则应在fts3tokenize声明中用逗号分隔(即使在常规fts4表的声明中以空格分隔)。下面创建使用相同标记器的fts4和fts3tokenize表:
使用fts4(tokenize = icu en_AU)创建虚拟表text1; 使用fts3tokenize(icu,en_AU)创建虚拟表tokens1; 使用fts4(tokenize = unicode61“ tokenchars = @。”“ separators = 123”)创建虚拟表text2; 使用fts3tokenize(unicode61,“ tokenchars = @。”,“ separators = 123”)创建虚拟表tokens2;
创建虚拟表后,可以按以下方式查询它:
SELECT令牌,开始,结束,位置 从tok1 WHERE input ='这是一个测试语句。';
虚拟表将为输入字符串中的每个令牌返回一行输出。“令牌”列是令牌的文本。“开始”和“结束”列是原始输入字符串中令牌开始和结束的字节偏移量。“位置”列是原始输入字符串中令牌的序列号。还有一个“输入”列,它只是WHERE子句中指定的输入字符串的副本。注意形式为“ input =?”的约束。必须出现在WHERE子句中,否则虚拟表将没有输入要标记化,并且将不返回任何行。上面的示例生成以下输出:
thi | 0 | 4 | 0 是| 5 | 7 | 1 a | 8 | 9 | 2 测试| 10 | 14 | 3 sentenc | 15 | 23 | 4
请注意,fts3tokenize虚拟表的结果集中的令牌已根据令牌生成器的规则进行了转换。由于此示例使用了“ porter”令牌生成器,因此“ This”令牌已转换为“ thi”。如果需要令牌的原始文本,则可以使用substr()函数的“ start”和“ end”列来检索令牌 。例如:
SELECT substr(input,start + 1,end-start),令牌,位置 从tok1 WHERE input ='这是一个测试语句。';
fts3tokenize虚拟表可以在任何令牌生成器上使用,无论是否存在实际使用该令牌生成器的FTS3或FTS4表。
本节从更高层次描述了FTS模块将其索引和内容存储在数据库中的方式。这是没有必要阅读或理解本节中的材料,以便使用FTS在应用程序中。但是,这对于尝试分析和了解FTS性能特征的应用程序开发人员,或正在考虑对现有FTS功能集进行增强的开发人员而言可能很有用。
对于数据库中的每个FTS虚拟表,将创建三到五个真实(非虚拟)表来存储基础数据。这些实际表称为“影子表”。实际表的名称为“%_content”,“%_ segdir”,“%_ segments”,“%_ stat”和“%_docsize”,其中“%”由FTS虚拟表的名称替换。
“%_content”表的最左列是一个名为“ docid”的INTEGER PRIMARY KEY字段。此之后是用户声明的FTS虚拟表的每一列的一列,名称的开头是用户提供的列名前面加上“ c N ”,其中N是表中列的索引,从左开始编号从0开始向右移动。作为虚拟表声明的一部分提供的数据类型不用作%_content表声明的一部分。例如:
-虚拟表声明 使用fts4(a NUMBER,b TEXT,c)创建虚拟表abc; -对应的%_content表声明 创建表abc_content(docid整数主键,c0a,c1b,c2c);
%_content表包含用户插入到FTS虚拟表中的纯净数据。如果用户在插入记录时未明确提供“ docid”值,则系统会自动选择一个值。
仅当FTS表使用FTS4模块而不是FTS3时才创建%_stat和%_docsize表。此外,如果FTS4表是使用在CREATE VIRTUAL TABLE语句中指定的“ matchinfo = fts3”指令创建的,则省略%_docsize表。如果创建了它们,则两个表的架构如下:
创建表%_stat( id整数主键, 值BLOB ); 创建表%_docsize( docid整数主键, 大小BLOB );
对于FTS表中的每一行,%_docsize表包含具有相同“ docid”值的对应行。“大小”字段包含由N个FTS varint组成的斑点,其中N是表中用户定义的列数。“大小” blob中的每个varint是FTS表中相关行的相应列中的令牌数。%_stat表始终包含一行,其“ id”列设置为0。“ value”列包含由N + 1个FTS varint组成的斑点,其中N 还是FTS表中用户定义的列数。Blob中的第一个varint设置为FTS表中的总行数。第二个及其后的varint包含存储在FTS表的所有行的相应列中的令牌总数。
剩下的两个表%_segments和%_segdir用于存储全文本索引。从概念上讲,此索引是一个查找表,该表将每个术语(单词)映射到与%_content表中包含一个或多个术语出现的记录相对应的一组docid值。要检索包含指定术语的所有文档,FTS模块将查询该索引以确定包含该术语的记录的docid值集,然后从%_content表中检索所需的文档。无论FTS虚拟表的架构如何,始终按以下方式创建%_segments和%_segdir表:
创建表%_segments( blockid INTEGER PRIMARY KEY, -B树节点ID 块blob -B树节点数据 ); 创建表%_segdir( 级别为INTEGER, idx INTEGER, start_block INTEGER, -%_segments中第一个节点的blockid leaves_end_block INTEGER, - %_segments中最后一个叶节点的Blockid end_block INTEGER, - %_segments中最后一个节点的Blockid 根BLOB, -B树根节点 主键(级别,IDX) );
上面描述的架构并非旨在直接存储全文索引。相反,它用于存储一个或多个b树结构。%_segdir表中的每一行都有一个b树。%_segdir表行包含根节点和与b树结构关联的各种元数据,而%_segments表包含所有其他(非根)b树节点。每个b树被称为一个“段”。创建后,分段b树永远不会更新(尽管可能会完全删除)。
每个段b树使用的键是术语(单词)。除键外,每个段b树条目都有一个关联的“文档列表”(文档列表)。一个文档列表包含零个或多个条目,其中每个条目包含:
文档列表中的条目按docid排序。文档列表条目中的位置以升序存储。
通过合并所有段b树的内容,可以找到逻辑全文索引的内容。如果一个术语存在于多个分段b树中,则它将映射到每个单个文档列表的并集。如果就单个术语而言,相同的docid出现在多个文档列表中,则只有属于最近创建的段b树的一部分的文档列表才被视为有效。
使用多个b树结构而不是单个b树,以减少将记录插入FTS表的成本。将新记录插入已经包含大量数据的FTS表中时,新记录中的许多术语可能已经存在于大量现有记录中。如果使用单个b树,则必须从数据库中加载大型doclist结构,对其进行修改以包括新的docid和term-offset列表,然后将其写回到数据库中。使用多个b树表可以避免这种情况,方法是创建一个新的b树,稍后再将其与现有b树(或多个b树)合并。b树结构的合并可以作为后台任务执行,或者一旦累积了一定数量的单独b树结构,即可进行合并。当然,
存储为段b树节点一部分的整数值使用FTS varint格式进行编码。这种编码是类似的,但不完全相同,于SQLite的varint格式。
编码的FTS varint占用一到十个字节的空间。所需的字节数由编码的整数值的正负号和大小确定。更准确地说,用于存储编码整数的字节数取决于整数值的64位二进制补码表示形式中最高有效位的位置。负值始终具有最高有效位集(符号位),因此始终使用完整的十个字节进行存储。正整数值可以使用更少的空间存储。
编码的FTS varint的最后一个字节的最高有效位被清除。前面的所有字节均设置了最高有效位。数据存储在每个字节的其余七个最低有效位中。编码表示的第一个字节包含编码整数值的最低有效七位。编码表示形式的第二个字节(如果存在)包含整数值的后七个最低有效位,依此类推。下表包含编码整数值的示例:
| 小数 | 十六进制 | 编码表示 |
|---|---|---|
| 43 | 0x000000000000002B | 0x2B |
| 200815 | 0x000000000003106F | 0x9C 0xA0 0x0C |
| -1 | 0xFFFFFFFFFFFFFFFF | 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0x01 |
段b树是前缀压缩的b +树。%_segdir表中的每一行都有一个分段b树(请参见上文)。段b树的根节点作为blob存储在%_segdir表的相应行的“根”字段中。所有其他节点(如果存在)都存储在%_segments表的“ blob”列中。%_segments表中的节点由相应行的blockid字段中的整数值标识。下表描述了%_segdir表的字段:
| 柱子 | 解释 |
|---|---|
| 等级 | 在它们之间,“级别”和“ idx”字段的内容定义了段b树的相对年龄。存储在“级别”字段中的值越小,则创建段b树的时间越近。如果两个段b树具有相同的“级别”,则存储在“ idx”列中的值较大的段是较新的段。%_segdir表上的PRIMARY KEY约束可防止任何两个段的“ level”和“ idx”字段具有相同的值。 |
| IDX | 看上面。 |
| start_block | 对应于具有最小块标识的节点的块标识,该节点属于此段b树。如果整个段b树适合根节点,则为零。如果存在,则此节点始终是叶节点。 |
| leaves_end_block | 对应于具有最大块标识的叶节点的块标识,该叶子节点属于此段b树。如果整个段b树适合根节点,则为零。 |
| end_block |
该字段可以包含一个整数或一个文本字段,该文本字段由两个以空格字符分隔的整数组成(Unicode代码点0x20)。
第一个或唯一的整数是与具有属于该分段b树的最大块标识的内部节点相对应的块标识。如果整个段b树适合根节点,则为零。如果存在,则此节点始终是内部节点。 第二个整数(如果存在)是叶子页上存储的所有数据的总大小(以字节为单位)。如果该值为负,则该段是未完成的增量合并操作的输出,并且绝对值为当前大小(以字节为单位)。 |
| 根 | 包含段b树的根节点的Blob。 |
除了根节点之外,构成单个段b树的节点始终使用连续的Blockid序列进行存储。此外,构成b树的单个级别的节点本身按b树顺序存储为连续块。从存储在相应的%_segdir行的“ start_block”列中的blockid值开始,以存储在b树叶子的blockid值的连续序列开始,并以存储在同一树的“ leaves_end_block”字段中的blockid值结束排。因此,可以通过按块ID顺序从“ start_block”到“ leaves_end_block”遍历%_segments表,从而以键顺序遍历段b树的所有叶子。
下图描述了段b树叶子节点的格式。
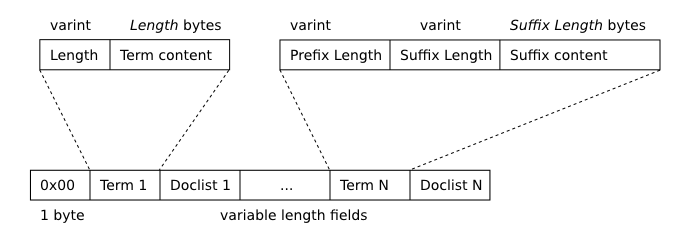
段B树树叶节点格式
每个节点上存储的第一项(上图中的“项1”)逐字存储。每个后续项都相对于其前任进行前缀压缩。术语以排序(memcmp)的顺序存储在页面中。
下图描述了分段b树内部(非叶子)节点的格式。
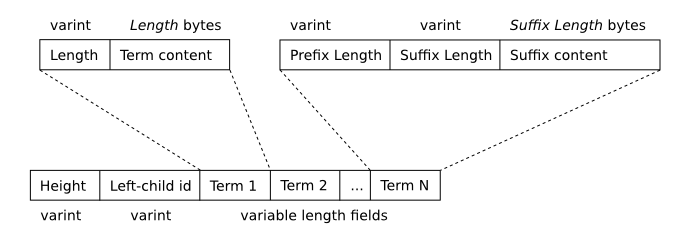
段B树内部节点格式
一个文档列表由一个64位带符号整数数组组成,这些数组使用FTS varint格式进行序列化。每个文档列表条目均由一系列两个或多个整数组成,如下所示:

FTS3 Doclist格式
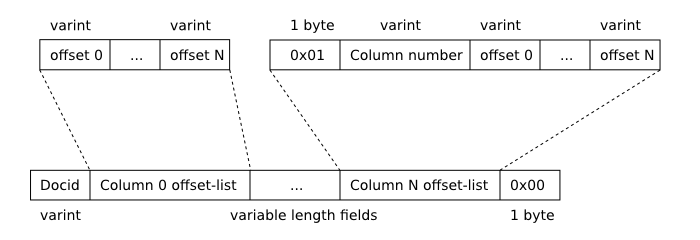
FTS Doclist输入格式
对于术语出现在FTS虚拟表的多列中的文档列表,文档列表中的术语偏移列表以列号顺序存储。这确保了与列0(如果有)关联的术语偏移列表始终是第一个,从而在这种情况下可以省略术语偏移列表的前两个字段。
在插入FTS3表的SQL字符串文字值的开始处嵌入了UTF-16字节顺序标记(BOM)。例如:
插入fts_table(col)VALUES(char(0xfeff)||'text ...');
SQLite转换为UTF-16字节顺序标记的格式错误的UTF-8嵌入在插入FTS3表的SQL字符串文字值的开头。
通过强制转换以两个字节0xFF和0xFE开头的blob创建的文本值将插入到FTS3表中。例如:
插入fts_table(col)VALUES(CAST(X'FEFF'AS TEXT));
FTS的主要目的是支持布尔全文查询-查找符合指定条件的文档集的查询。但是,许多(大多数?)搜索应用程序要求以某种方式对结果进行“相关性”排序,其中“相关性”定义为执行搜索的用户对返回的文档集中的特定元素感兴趣的可能性。当使用搜索引擎在万维网上查找文档时,用户期望将最有用或“相关”的文档作为结果的第一页返回,并且随后的每个页面包含的相关性逐渐降低。机器如何根据用户查询确定文档的相关性是一个复杂的问题,也是许多正在进行的研究的主题。
一个非常简单的方案可能是计算每个结果文档中用户搜索词的实例数。与包含每个术语少量实例的那些文档相比,包含多个术语实例的那些文档被认为更相关。在FTS应用程序中,可以通过对offsets函数的返回值中的整数进行计数来确定每个结果中的术语实例数。以下示例显示了一个查询,该查询可用于获取用户输入的查询的十个最相关的结果:
-此示例(以及本节中的所有其他示例)采用以下架构 使用fts3(title,content)创建虚拟表文档; -假设应用程序提供了一个名为“ countintegers”的SQLite用户函数 -返回其唯一参数中包含的以空格分隔的整数的数量, -以下查询可用于返回包含以下内容的10个文档的标题 -用户查询字词的实例最多。希望这些十个 文档将成为用户或多或少认为最“相关”的文档。 从文件中选择标题 WHERE文档MATCH <查询> ORDER BY countintegers(offsets(documents))DESC 极限10偏移0
通过使用FTS matchinfo 函数来确定出现在每个结果中的查询词实例的数量,可以使上面的查询运行得更快。matchinfo函数比offsets函数高效得多。此外,matchinfo函数提供有关整个文档集中每个查询词的总出现次数(不仅是当前行)以及每个查询词出现在其中的文档数的更多信息。这可以用于(例如)将较高的权重附加到不太常见的术语上,这可能会增加用户认为更有趣的那些结果的总体计算相关性。
-如果应用程序提供了一个称为“ rank”的SQLite用户函数,该函数 解释了matchinfo返回的数据块并 基于其 返回数字相关性,则可以使用以下SQL返回以下内容的标题:用户查询的数据集中10个最相关的文档。 从文件中选择标题 WHERE文档MATCH <查询> ORDER BY rank(matchinfo(documents))DESC 极限10偏移0
上面的示例中的SQL查询使用的CPU比本节中的第一个示例少,但仍然存在明显的性能问题。SQLite通过在用户排序和限制结果之前从FTS模块中为用户查询匹配的每一行检索“ title”列的值和matchinfo数据来满足此查询。由于SQLite的虚拟表接口的工作方式,要检索“ title”列的值需要从磁盘加载整行(包括“ content”字段,该字段可能很大)。这意味着,如果用户查询匹配数千个文档,则即使它们永远不会用于任何目的,也可能将许多兆字节的“标题”和“内容”数据从磁盘加载到内存中。
以下示例块中的SQL查询是解决此问题的一种方法。在SQLite中,当联接中使用的子查询包含LIMIT子句时,在执行主查询之前,将计算该子查询的结果并将其存储在临时表中。这意味着SQLite将仅将与用户查询匹配的每一行的docid和matchinfo数据加载到内存中,确定与十个最相关的文档相对应的docid值,然后仅仅加载这十个文档的标题和内容信息。由于matchinfo和docid值均完全从全文索引中收集,因此导致从数据库加载到内存的数据大大减少。
从文件中选择标题JOIN(
SELECT docid,rank(matchinfo(documents))AS排名
来自文件
WHERE文档MATCH <查询>
按等级排序
极限10偏移0
)AS排名表使用(docid)
ORDER BY ranktable.rank DESC
下一个SQL块通过解决使用FTS开发搜索应用程序时可能出现的其他两个问题的解决方案来增强查询:
该片断功能不能与上述查询中使用。因为外部查询不包含“ WHERE ... MATCH”子句,所以代码片段功能可能无法与其一起使用。一种解决方案是在外部查询中复制子查询使用的WHERE子句。与之相关的开销通常可以忽略不计。
文档的相关性可能不仅取决于matchinfo的返回值中可用的数据。例如,可以基于与其内容无关的因素(来源,作者,年龄,参考文献数量等)为数据库中的每个文档分配静态权重。这些值可以由应用程序存储在一个单独的表中,该表可以与子查询中的documents表联接在一起,以便rank函数可以访问它们。
该查询版本与sqlite.org文档搜索 应用程序使用的查询版本非常相似 。
-该表将分配给每个文档的静态权重存储在FTS表
-“文档”中。对于documents表中的每一行,都有一个对应的行
-该表中的docid值相同。
创建表document_data(docid INTEGER PRIMARY KEY,weight);
-此查询是一个类似于在上面的块,不同之处在于:
-
- 1.与文档标题为显示沿着返回文本的“片段”。因此
,为了使用摘要功能,
子查询中
的“ WHERE ... MATCH ...”子句在外部查询中重复。-
- 2.子查询连接的文件表与document_data表,让
-实施RANK函数的访问分配静态重量
-每个文档。
SELECT title,snippet(documents)FROM document JOIN(
SELECT docid,rank(matchinfo(documents),documents_data.weight)AS排名
FROM文档JOINdocuments_data使用中(docid)
WHERE文档MATCH <查询>
按等级排序
极限10偏移0
)AS排名表使用(docid)
WHERE文档MATCH <查询>
ORDER BY ranktable.rank DESC
上面所有示例查询均返回十个最相关的查询结果。通过修改与OFFSET和LIMIT子句一起使用的值,可以轻松构造一个查询以返回(说)下十个最相关的结果。这可用于获取搜索应用第二页和后续结果页所需的数据。
下一个块包含一个示例等级函数,该函数使用在C中实现的matchinfo数据。它代替单个权重,允许将权重从外部分配给每个文档的每一列。可以像其他任何使用sqlite3_create_function的用户函数一样,将其注册到SQLite 。
安全警告:因为它只是一个普通的SQL函数,所以rank()可以在任何上下文中作为任何SQL查询的一部分被调用。这意味着传递的第一个参数可能不是有效的matchinfo blob。实现者应谨慎处理这种情况,而不会导致缓冲区溢出或其他潜在的安全问题。
/ *
** SQLite用户定义函数,可与matchinfo()一起使用,以计算
FTS匹配
的**相关性。返回的值是相关性分数**(大于或等于零的实际值)。较大的值表示
**相关性更高的文档。
**
**返回的总体相关性是
FTS表
中每个**列值的相关性的总和。列值的相关性是FTS查询中每个可报告短语的以下各项的总和:
**
**(<命中计数> / <全局命中计数>)* <列权重>
**
**其中<命中计数>是
当前行的**列值中短语的实例数,而<global hit count>是该数
FTS
**表
中所有行的同一列中的短语实例的**。<column weight>是调用者
分配给每个**列的加权因子(请参见下文)。**
**此函数的第一个参数必须是FTS
** matchinfo()函数
的返回值。在此之后必须是FTS表的
每一列**的一个参数,其中包含对应**列
的数字权重因子。示例:**
**使用fts3(title,content)创建虚拟表文档
**
**以下查询返回与全文
查询**查询<query>匹配的文档的docid,这些查询从最相关到最不相关。计算时
**相关性,“标题”列中的查询字词实例的
权重是“内容”列中
实例的权重的两倍。**
**从文档中选择docid
**在文档中匹配<query>的地方
** ORDER BY BY rank(matchinfo(documents,1.0,0.5)DESC
* /
静态void rankfunc(sqlite3_context * pCtx,int nVal,sqlite3_value ** apVal){
int * aMatchinfo; / * matchinfo()的返回值* /
int nMatchinfo; / * aMatchinfo []中的元素数* /
int nCol = 0; / *表中的列数* /
int nPhrase = 0; / *查询中短语的数量* /
int iPhrase; / *当前词组* /
双分数= 0.0; / *返回值* /
断言(sizeof(int)== 4);
/ *检查传递给此函数的参数数量是否正确。
**如果不是,请跳转至错误代码_参数。将aMatchinfo设置为指向
FTS函数matchinfo返回的无符号整数值
数组**。设置 ** nPhrase以包含用户全文
查询中
的可报告短语的数量,并将nCol设置为表中的列数。然后检查 matchinfo blob
的**大小是否符合预期。如果不是,则返回错误。 * /
if(nVal <1)转到rong_number_args;
aMatchinfo =(unsigned int *)sqlite3_value_blob(apVal [0]);
nMatchinfo = sqlite3_value_bytes(apVal [0])/ sizeof(int);
if(nMatchinfo> = 2){
nPhrase = aMatchinfo [0];
nCol = aMatchinfo [1];
}
if(nMatchinfo!=(2 + 3 * nCol * nPhrase)){
sqlite3_result_error(pCtx,
“传递给函数rank()的无效matchinfo blob”,-1);
返回;
}
if(nVal!=(1 + nCol))转到rong_number_args;
/ *遍历用户查询中的每个短语。* /
for(iPhrase = 0; iPhrase <nPhrase; iPhrase ++){
int iCol; / *当前列* /
/ *现在遍历用户查询中的每一列。对于每一列,
**通过以下方式使相关性得分递增:
**
**(<命中计数> / <全局命中计数>)* <列权重>
**
** aPhraseinfo []指向短语iPhrase的数据开头。因此,
**每一行的命中计数和全局命中计数分别在
** aPhraseinfo [iCol * 3]和aPhraseinfo [iCol * 3 + 1]中找到。
* /
int * aPhraseinfo =&aMatchinfo [2 + iPhrase * nCol * 3];
for(iCol = 0; iCol <nCol; iCol ++){
int nHitCount = aPhraseinfo [3 * iCol];
int nGlobalHitCount = aPhraseinfo [3 * iCol + 1];
双权重= sqlite3_value_double(apVal [iCol + 1]);
if(nHitCount> 0){
得分+ =((double)nHitCount /(double)nGlobalHitCount)*权重;
}
}
}
sqlite3_result_double(pCtx,分数);
返回;
/ *如果将错误数量的参数传递给此函数,请跳至此处* /
错误的数字参数:
sqlite3_result_error(pCtx,“函数rank()的参数个数错误”,-1);
}